

Softwareentwicklung: Die Performance von Java Logging
Für Java gibt es eine Fülle an verschiedenen Logging-Bibliotheken und Möglichkeiten, Log-Nachrichten auszugeben. Aber welche davon sind wirklich performant?

(Bild: Open Elements)
- Hendrik Ebbers
In den vorherigen Posts zum Thema Java Logging (Best Practices, Logging Facades) habe ich bereits erwähnt, dass es eine Fülle an Java Libraries zum Thema Logging gibt. Nachdem wir im letzten Post geklärt haben, wie man mit einer Facade verschiedene Logger vereinen kann, wollen wir uns nun die Performance von Logging-Bibliotheken anschauen.

Performance-Messung in Java
Um kleine Teile einer Java-Anwendung oder -Bibliothek mittels eines Benchmarks zu überprüfen, gibt es in Java das Tool Java Microbenchmark Harness (JMH), das vom OpenJDK bereitgestellt wird, um Performance-Benchmarks durchzuführen. Es führt ähnlich wie bei Unit-Tests kleine Teile der Anwendung (Micro-Benchmarks) aus und analysiert sie. Hierbei kann man unter anderem einstellen, ob der Code zuvor mehrfach für ein paar Sekunden ohne Messung durchlaufen soll, um die JVM und JIT "warmzulaufen".
Diese und andere Parameter lassen sich bei JMH ähnlich wie bei JUnit einfach durch Annotations definieren. Ein simples Beispiel für einen Benchmark sieht folgendermaßen aus:
@Benchmark
@BenchmarkMode(Mode.Throughput)
@Warmup(iterations = 4, time = 4)
@Measurement(iterations = 4, time = 4)
public void runSingleSimpleLog() {
logger.log("Hello World");
}Das Beispiel führt vier Durchläufe zum Aufwärmen durch, gefolgt von vier Messdurchläufen. Jeder Durchlauf dauert vier Sekunden, und das Messergebnis zeigt an, wie viele Operationen pro Sekunde durchgeführt werden konnten. Konkret bedeutet das, wie oft "Hello World" geloggt werden konnte. Das Ganze bekommt man nach dem Durchlauf tabellarisch in der Kommandozeile ausgegeben, kann es aber auch beispielsweise als JSON- oder CSV-Datei speichern.
Performance-Messung für Java Logger
Mithilfe von JMH habe ich einen Open-Source-Benchmark für Logging-Frameworks erstellt, das bei GitHub einsehbar ist. Er überprüft aktuell folgende Logging-Bibliotheken beziehungsweise Set-ups auf ihre Performance:
- JuL (java.util.logging) mit Logging auf die Konsole
- JuL (java.util.logging) mit Logging in ein File
- JuL (java.util.logging) mit Logging auf die Konsole und in ein File
- SLF4J Simple mit Logging in ein File
- Log4J2 mit Logging auf die Konsole
- Log4J2 mit Logging in ein File
- Log4J2 mit Logging auf die Konsole und in ein File
- Log4J2 mit asynchronen Logging in ein File
- Chronicle Logger mit asynchronen Logging in ein File
Für jede dieser Konstellation gibt es verschiedene Benchmarks, die die Performance vom Erstellen des Logger über das Loggen einer einfachen "Hello World"-Nachricht bis hin zu komplexen Logging-Aufrufen (Placeholder in Message, Marker, MDC Nutzung, etc.) messen.
Die Messungen zeigen, dass Logging-Frameworks generell sehr performant sind. Auf der anderen Seite führten sie aber auch ein paar Erkenntnisse zutage, die sicherlich nicht jedem direkt klar sind.
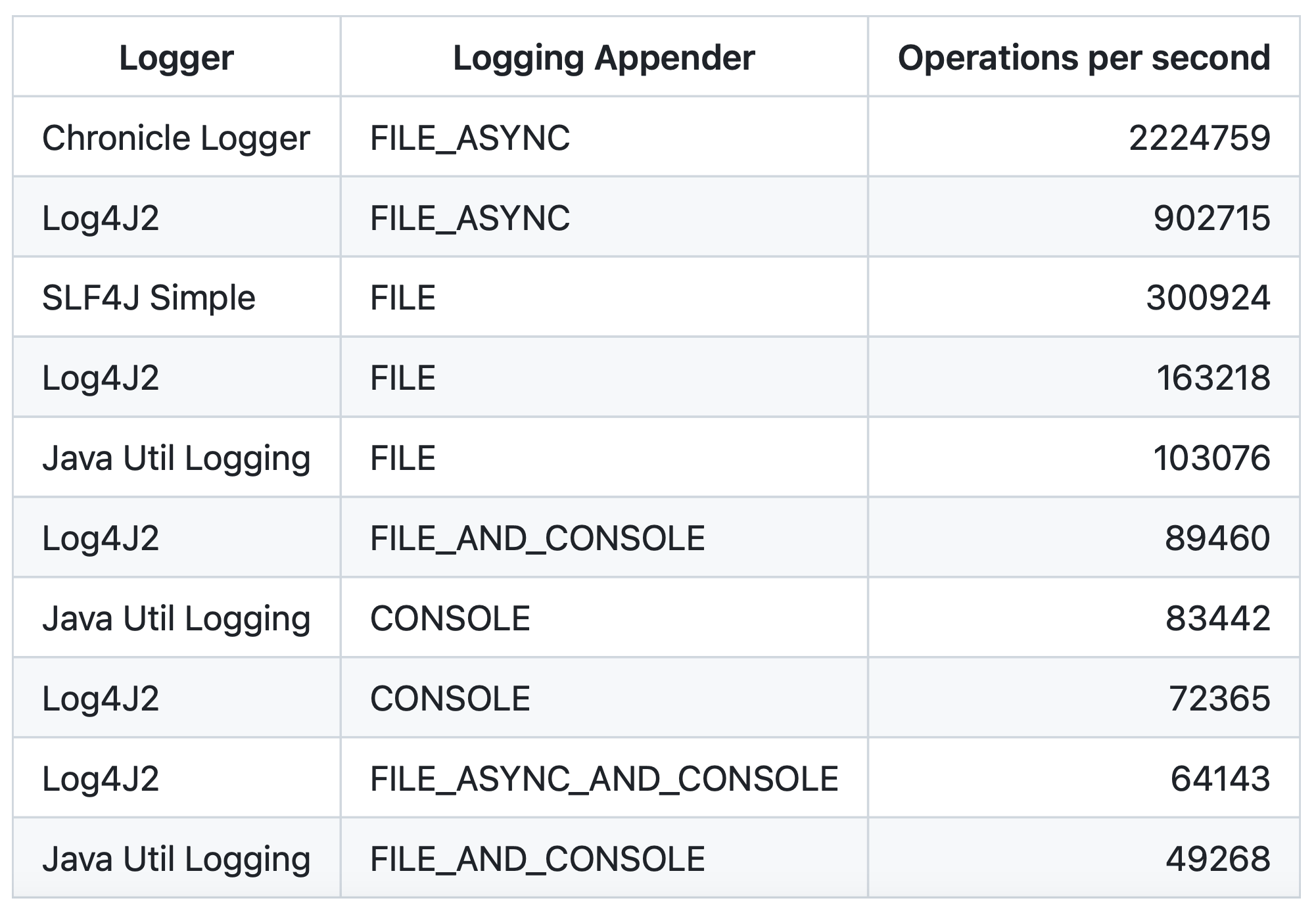
Im Folgenden findet sich eine Übersicht von Messergebnissen beim einfachen Loggen einer "Hello World" Nachricht:
Das Problem mit der Konsole
Ein erstes Ergebnis der Messungen ist, dass ein Logging auf die Konsole immer deutlich langsamer ist als ein Logging ins Dateisystem. Während man beim Logging in eine Datei 200.000 bis 300.000 Aufrufe des Loggers pro Sekunde erreichen kann, sind es bei einer Ausgabe auf die Konsolen immer deutlich unter 100.000 Operationen die Sekunde gewesen. Da alle Logging-Libraries hier mit System.out bzw. System.err arbeiten, macht es auch kaum einen Unterschied in der Performance, welche Bibliothek man nutzt. Hier wird es in Zukunft spannend zu schauen, ob man durch Tricks oder Umbauten eine bessere Performance hinbekommen kann.
Synchrones und Asynchrones Logging in Files
Einen weiteren großen Unterschied sieht man, wenn man die Messwerte von synchronen bzw. asynchronen Logging in eine Datei betrachtet. Hier wird sofort deutlich, dass asynchrones Logging deutlich schneller ist. Die folgenden Tabellen zeigen die Messwerte von asynchronen Logging im Vergleich zu synchronen Logging:

Die klar erkennbar höherer Performance liegt daran, dass die Schreiboperation der asynchronen Logger nicht blockiert. Die Logger Log4J2 und Chronicle Logger nutzen zwar intern unterschiedliche Bibliotheken intern, basieren aber beide auf einer "lock-free inter-thread communication library". Während bei Log4J hierbei LMAX Disruptor als Bibliothek hinzugefügt werden muss, die intern über Ringbuffer das asynchrone Logging ermöglicht, basiert der Chronicle Logger direkt auf der Chronicle Queue Bibliothek.

Konkrete Beschreibung der intern genutzten Libraries und wie diese eine asynchrone Kommunikation beziehungsweise das Schreiben ins Dateisystem ermöglichen, lässt sich der Dokumentation entnehmen.
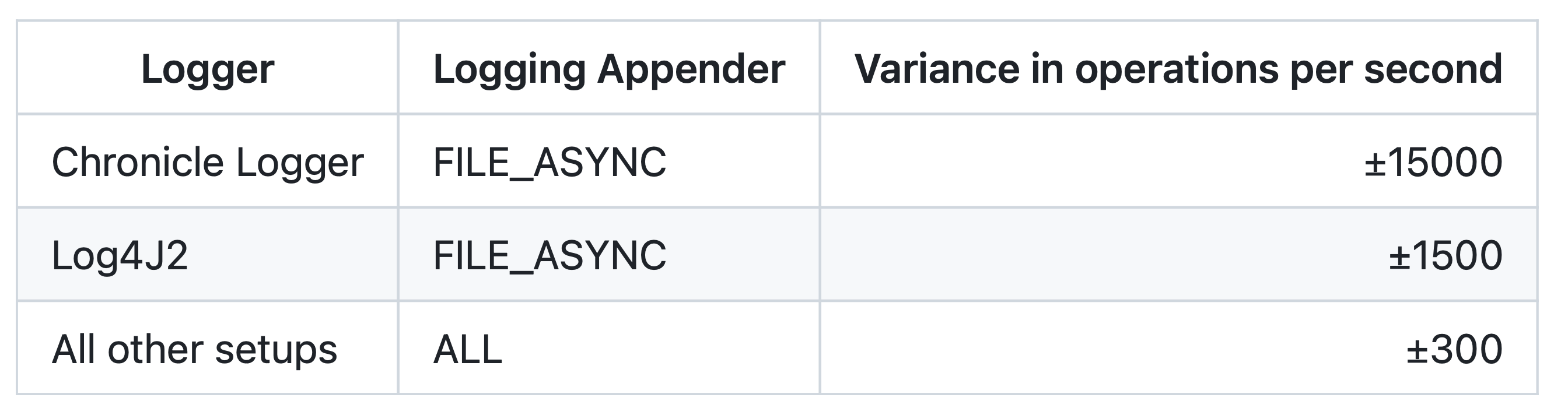
Wenn man die Performance von Log4J2 und Chronicle Logger vergleicht, kann man sehen, dass der Chronicle Logger noch einmal deutlich schneller ist. Dieser Performance-Vorteil kommt aber auch mit einem Nachteil, dem man sich bewusst sein muss: Während Log4J2 auch im asynchronen Modus weiterhin zeilenweise ein für den Menschen einfach lesbares Logging im Dateisystem erzeugt, schreibt der Chronicle Logger alle Nachrichten in einem Binärformat. Hier wird zum Lesen bzw. Parsen dann ein Tooling benötigt, das der Logger aber mitliefert. Darüber hinaus ist die Varianz der Testergebnisse des Chronicle Logger deutlich höher. Als Grund vermute ich, dass die genutzt Chronicle Queue die binären Daten zum Schreiben des Logging intern verwaltet und deren Größen immer dynamisch anpasst. Dies muss allerdings noch weiter untersucht werden. Die folgende Tabelle zeigt einmal eine Übersicht der Varianz:
Fazit
Wie man sehen kann, ist nicht nur die Wahl einer Logging Bibliothek, sondern auch deren Konfiguration extrem wichtig für die Performance. Während das Logging auf die Konsole während der Entwicklung sicherlich sehr angenehm ist, kann man sich beispielsweise überlegen, ob die Nutzung des Konsolen-Logging im Live-Betrieb wirklich immer erforderlich ist. Auch zeigt sich, dass eine Nutzung von asynchronen Loggern sinnvoll sein kann, wenn die Performance des Systems wirklich kritisch ist. Das kommt aber natürlich mit einer höheren Komplexität und zusätzlichen transitiven Abhängigkeiten einher. Letztlich muss also jedes Projekt weiterhin selbst für sich entscheiden, welcher Logger am sinnvollsten ist. Durch die hier genannten Zahlen hat man aber nun eine weitere Basis, um das festzulegen.
(rme)
