

Wolkenintelligenz: AWS-Instanzen für Künstliche Intelligenz und Machine Learning
Sowohl das Training als auch der produktive Einsatz großer ML-Modelle kann sehr rechenintensiv sein. Es liegt nahe, diese Aufgaben in die Cloud zu verlagern.

Wolkenintelligenz: AWS AI/ML-Instanzen
(Bild: istockphoto.com, Andy)
- Lars Röwekamp
Kaum ist die Welt der "Hello-World" ML-Modelle verlassen, stößt der heimische Laptop oder PC schnell an seine Grenzen. Dabei erweist sich nicht nur die GPU als Flaschenhals. Auch andere Faktoren, wie zum Beispiel der gemeinsame Speicher, 1st- und 2nd-Level-Caches oder der Durchsatz, spielen eine wichtige Rolle. Die richtige Kombination ist entscheidend.

Wie sieht die optimale KI-/ML-Instanz aus?
Wie stark die einzelnen Faktoren ins Gewicht fallen, hängt unter anderem davon ab, welches konkrete ML-Modell verwendet wird und welche Art und Menge von Daten dabei zum Einsatz kommen. Zusätzlich unterscheiden sich die Anforderungen während des Trainings eines Modells zum Teil stark von denen im produktiven Einsatz zum Generieren von Vorhersagen (engl. Inference). Und auch hier gilt wieder, dass die Unterschiede zwischen Training und Inference stark vom verwendeten Modell und den Daten beeinflusst werden.
Eine Pauschalaussage, welche die beste KI-/ML-Hardware ist, gibt es nicht. Vielmehr hängt die richtige Wahl vom jeweils gegebenen Kontext ab. Bevor also Unsummen in Hardware investiert werden, die in möglichst vielen Kontexten ein gutes Resultat abwirft, lohnt sich ein Blick auf das reichhaltige Angebot der verschiedenen Cloud-Provider. Genau das werde ich in unregelmäßigen Abständen immer mal wieder in diesem Blog tun. Den Anfang mache ich mit dem Angebot von Amazon Web Services.
Genau das geschieht in den drei Artikeln der Serie Wolkenintelligenz:
- AWS-Instanzen für künstliche Intelligenz und Machine Learning
- Optimierte Ressourcen für künstliche Intelligenz und Machine Learning in Azure
- Google Cloud Machine Learning Engines
Warum gerade mit AWS starten? Zum einen hat AWS, zumindest meiner persönlichen Meinung nach, das wohl breiteste Angebot an GPU-basierten Rechnerinstanzen. Zum anderen, und das ist vielleicht noch ausschlaggebender, ist das Angebot von AWS auf den ersten Blick nicht wirklich transparent und somit die Wahl der passenden Instanz alles andere als trivial. Hier möchte ich gerne ein wenig Licht ins Dunkel bringen.

(Bild: open knowledge)
Last but not least bietet sich AWS als KI-/ML-Instance-Provider für all diejenigen an, die sich bereits mit ihren Daten und Anwendungen in der AWS Cloud tummeln. Dies dürften nach einschlägigen Reports nicht wenige sein. Aber keine Angst, natürlich werde ich in den kommenden Monaten auch das Angebot von Google Cloud, Microsoft Azure und anderen unter die Lupe nehmen.
GPU vs. CPU
Um beurteilen zu können, welche Cloud-Instanz die passende für einen konkreten KI-/ML-Anwendungsfall ist, gilt es zunächst zu verstehen, welche Herausforderungen er an die zugrundeliegende Infrastruktur stellt.
Starten wir zunächst einmal mit der Fragestellung, warum überhaupt GPUs einen Vorteil gegenüber CPUs bringen können und welche Eigenschaften die GPU dazu mitbringen muss.
Während CPUs immer dann ihre Stärke ausspielen, wenn es darum geht, viele kleine unabhängige Tasks sequenziell zu verarbeiten, sind GPUs prädestiniert für Szenarien, in denen große Rechenprozesse aufgesplittet und parallel verarbeitet werden können. Genau diese Szenarien finden wir in typischen Deep-Learning-Problemen, die in der Regel mit Neuronalen Netzen bearbeitet werden. Unter der Haube finden unzählige mathematische Operationen auf Matrizen statt, deren Berechnungen sich sehr gut parallelisieren und am Ende wieder zusammenführen lassen. Man spricht daher bei GPUs auch von Vertretern der Single Instruction, Multiple Data (SIMD) Architecture.

(Bild: open knowledge)
CUDA / Tensor Cores: Sowohl CUDA Cores als auch Tensor Cores sind speziell für die parallele Verarbeitung optimierte Architekturen von Nvidia. Man kann sie als äquivalent zu den CPU-Kernen sehen, wobei CUDA bzw. Tensor Cores deutlich weniger komplex sind und in entsprechend höherer Anzahl – durchaus mehrere tausend – vorkommen. Während CUDA Cores allgemeiner ausgelegt sind und lediglich eine Multiplikation pro GPU-Zyklus durchführen können, sind Tensor Cores deutlich spezialisierter und erlauben die Multiplikation kleiner Matrizen. Dies führt insbesondere bei Neuronalen Netzen zu einer erheblichen Beschleunigung, allerdings auf Kosten der Genauigkeit. CUDA Cores finden sich sowohl auf GPUs von Nvidia als auch auf AMD GPUs. Tensor Cores dagegen gibt es nur auf den GPUs von Nvidia.
Memory Bandwith: Tensor Cores arbeiten extrem schnell. So schnell, dass sie häufig darauf warten, vom Speicher mit neuen Daten versorgt zu werden. Entsprechend wichtig ist die Speicherbandbreite. Vergleicht man beispielsweise die Bandbreiten der beiden Nvidia GPUs Tesla A100 und Tesla V100, so zeigt sich, dass allein schon die verbesserte Speicherbandbreite von 1.555 GB/s (A100) vs. 900 GB/s (V100) eine Beschleunigung mit einem höheren Faktor als 1,5 mit sich bringen kann.
Shared Memory: Wie eben beschrieben, ist der Transfer der Daten zu den Rechenkernen (CUDA oder Tensor Cores) einer der wesentlichen Faktoren, wenn es um die Geschwindigkeit einer GPU geht. Schafft man es also, die Daten näher an deren Verarbeitungsort zu bringen, lässt sich die Verarbeitung entsprechend beschleunigen. Neben dem langsamen globalen Speicher kommen hier die lokalen Caches L1 und L2, sowie die Register ins Spiel. Der Trick ist nun, diese von ihrer Dimensionierung so zu wählen, dass Daten innerhalb der Hierarchie mehrfach wiederverwendet werden können und so nicht vom globalen Speicher neu angefragt werden müssen. Es gilt dabei aber nicht generell "je mehr desto besser". Vielmehr kommt es auf die Feinabstimmung der verschiedenen Speicherstufen auf die Möglichkeiten der Rechenkerne an. Tim Dettmers beschreibt diesen Zusammenhang sehr gut und detailliert in seinem Blogartikel TPU vs GPU for Transformers.
Interconnection: Die bisher skizzierten Eigenschaften, bezogen sich immer nur auf eine GPU. In der Praxis ist es aber durchaus üblich, die Rechenlast auf viele Instanzen zu verteilen. Das gilt insbesondere für große Modelle und viele Daten. Durch die speziellen Anforderungen an den Austausch der Instanzen untereinander, haben sich in den letzten Jahren neben PCI-Express weitere Mechanismen, wie NV-Link oder NV-Switch, zur optimierten Multi-GPU-Kommunikation entwickelt.
Nachdem wir nun gelernt haben, worauf es bei der Auswahl der passenden GPU-Instanz zu achten gilt, wagen wir uns nun in den AWS GPU-Jungle.
Welcome to the AWS GPU-Jungle
AWS unterscheidet bei seinen GPU-Instanzen im Wesentlichen zwei Familien namens P- und G-Instanzen. Die Nomenklatur ergibt sich historisch aus den ursprünglich angedachten Einsatzgebieten.
Die P-Familie war initial für den Einsatz im Umfeld von High-Performance-Computing (HPC) angedacht und zeichnet sich entsprechend durch höhere Leistung (u.a. höhere Wattleistung, mehr CUDA-Cores) und Unterstützung des Double-Precision Floating-Point Formats (FP64) aus, das für wissenschaftliche Berechnungen verwendet wird. Die G-Familie dagegen wurde für den kostengünstigeren Einsatz im Bereich Graphics und Rendering konzipiert, bringt entsprechend weniger Leistung mit (u.a. geringere Wattleistung, weniger CUDA-Cores) und verzichtet auf das Double-Precision Floating-Point Format.
Mittlerweile sind die Grenzen zwischen den beiden EC2-GPU-Instanzenfamilien allerdings verschwommen, sodass sich beide für den ML-Einsatz eignen. Der Fokus der P-Familie liegt nach wie vor auf HPC-Szenarien und dem Training großer, datenintensiver Modelle. Die G-Familie dagegen kann gut (und relativ günstig) für das Training überschaubarer Modelle sowie die Bereitstellung trainierter Modelle zur Vorhersage verwendet werden.
Folgende Abbildung zeigt die Einordnung der beiden GPU-Instanz-Familien inkl. ihrer historischen Entwicklung und physikalischen GPUs. Die Nummern neben der P-/G-Kennung geben die jeweilige Generation an.

(Bild: open knowledge)
Alles, was geht
Aus der obigen Grafik wird deutlich, dass die auf NVIDIA H100 Tensor Core GPUs und somit auf der NVIDIA-Hopper-Architektur basierenden EC2-P5-Instanzen das aktuelle Nonplusultra in der AWS-Cloud darstellen. Laut AWS sogar das Nonplusultra in der gesamten Cloud, wenn es um das verteilte Training von extrem großen ML-Modellen geht!
P5-Instanzen gibt es aktuell in der Ausführung p5.48xlarge mit bis zu 8 H100 GPUs und insgesamt bis zu 640 GByte HBM3 GPU-Speicher. Sie ermöglichen mittels Elastic Fabric Adapter (EFAv2) eine aggregierte Bandbreite von bis zu 3.200 GB/s und erlauben dank NVIDIA GPUDirect RDMA die direkte Kommunikation von GPU zu GPU unter Umgehung des Betriebssystems beziehungsweise der CPU.
Die neuen P5-Instanzen übertreffen damit das bisherige Spitzenmodell der AWS-Cloud - die P4-Instanzen – in allen Belangen um Längen.
Die Bereitstellung der P5-Instanzen erfolgt innerhalb eines EC2 UltraClusters der zweiten Generation. EC2 UltraClusters der zweiten Generation kombinieren Hochleistungs-Computing mit fortschrittlicher Netzwerk- und Speicherfunktion und erlauben so eine Skalierung von bis zu 20.000 H100 GPUs. Sie sind nicht für den Hausgebrauch, sondern für das Training extrem großer Modelle wie LLMs (Large Language Models) mit generativer AI ausgelegt.

(Bild: P4 Instances von AWS EC2 )
Aufgrund der hohen Bandbreite und der hervorragenden Verbindung der GPUs untereinander, ist die P5-Instanz sowohl für das parallele Trainieren von Modellen mit auf GPUs verteilten Daten (data parallel training) geeignet als auch für das parallele Training großer, gesplitteter Modelle (Model Parallel Training), die als Ganzes nicht in eine GPU passen würden.
Die enorme Leistung der P5-Instanzen hat ihren Preis: Laut AWS-Preisliste schlägt eine einzelne P5-Instanz in der on-Demand-Variante mit etwa 100 Euro/h zu buche. Wer sich auf einen längeren Nutzungszeitraum festlegt, kann die Kosten pro Stunde etwa halbieren. Auch wenn das für die enorme Leistung überschaubar klingt, summieren sich die Rechnungen in realen Szenarien kräftig.
Laut Aussage von AWS kann die neue Generation 5 der P-Familie den Aufwand für das Training großer Modelle um einen Faktor von bis zu sechs im Vergleich zu einer P4-Instanz verringern – bei gleichzeitiger Kostenreduktion um bis zu 40 %. Der höhere Preis pro Stunde dürfte sich demnach bald amortisieren.
Einen kleinen Wermutstropfen gibt es allerdings noch: Aktuell stehen P5-Instanzen lediglich in den Regionen US East und US West bereit
Geht’s auch etwas günstiger?
Wer nicht ganz so tief in die Tasche greifen will und im Gegenzug mit etwas weniger Leistung zufrieden ist, der ist mit den P3-Instanzen bestens bedient.
P3-Instanzen basieren auf NVIDIA V100 GPUs und entsprechend auf der etwas älteren NVIDIA-Volta-Architektur. Jede GPU verfügt über 16 GByte Speicher. P3-Instanzen gibt es sowohl in einer Single-GPU-Variante (p3d.2xlarge) als auch in mehreren Multi-GPU-Varianten (p3.8xlarge, p3.16xlarge, p3dn.24xlarge), die sich durch Anzahl der GPUs (4 oder 8) und Größe des Speichers (16 GB oder 32 GB) unterscheiden. Die Kommunikation zwischen den GPUs findet bei den Multi-GPU-Instanzen via NVLink der zweiten Generation und somit mit 300 GB/s statt. Die Preise der verschiedenen Varianten variieren zwischen ca. 2 Euro/h und 18 Euro/h. Noch günstiger wird es, wenn man die Ressourcen über einen längeren Zeitraum reserviert. Hier können Preise von ca. 1 Euro/h für die günstigste Instanz und einen Zeitraum von 3 Jahren erreicht werden.
Da es die P4-Instanz nur als 8-GPU-Variante gibt, bietet P3 aktuell die leistungsstärkste Single-GPU-Instanz in der AWS-Cloud.
Aber ich habe doch kein Geld
Wem die Preise der P3-Instanzen immer noch zu hoch sind, bietet AWS mit den recht neuen G5-Instanzen eine gute und relativ günstige Alternative. G5-Instanzen basieren, wie die P4-Instanzen, auf der NVIDIA-Ampere-Architektur, wobei hier mit NVIDIA A10G das weniger leistungsstarke Pendant der NVIDIA A100 zum Einsatz kommt.
G5-Instanzen sind immer dann interessant, wenn eine Single-GPU und 24 GByte für das Training oder die Bereitstellung eines ML-Modells ausreichen. Je nach gewählter Instanz (g5.xlarge, g5.2/4/8/16xlarge) stehen 4 bis 64 vGPUs zu einem Preis von ca. 1 Euro/h bis ca. 4 Euro/h zur Verfügung. G5-Instanzen bieten somit ein sehr gutes, wenn nicht das beste Preis-Leistungs-Verhältnis innerhalb der AWS-GPU-Instanzen.
Neben der genannten Single-GPU-Variante bietet AWS die G5-Instanzen auch als 4- oder 8-GPU-Varianten mit entsprechend mehr vGPUs (48 bis 192) an. Die Interconnection zwischen den GPUs variiert je nach gewählter Variante zwischen 25 GB/s und 100 GB/s und ist somit selbst in der besten Variante deutlich langsamer als bei den P3- und P4-Instanzen.
Noch günstiger wird es mit den G4-Instanzen, dem direkten Vorläufer der G5-Instanzen. Auch hier gibt es wieder sowohl Single-GPU- als auch Multi-GPU-Varianten. Zusätzlich wird zwischen NVIDIA-GPUs (G4dn, NVIDIA T4) und AMD-GPUs (G4ad, AMD Radeon Pro V520 und AMD EPYC) unterschieden, wobei sich für Machine-Learning-Workloads, wie zum Beispiel das Training von kleinen bis mittleren Modellen oder der Bereitstellung von trainierten Modellen, insbesondere die NVIDIA-GPUs eignen. Die AMD-GPUs dagegen sind eher für Grafikanwendungen optimiert. Die einzelnen GPUs sind mit 16 GByte ausgestattet. Die Kommunikation der GPUs untereinander findet über PCIe statt.
Die Preise der Single-GPU-Varianten starten bei ca. 50 Cent/h (g4ad.xlarge: 4 vGPUs, 16 GByte Arbeitsspeicher, 10 GB/s Bandbreite) und gehen hoch bis ca. 4 Euro/h (g4dn.16xlarge: 64 vGPUs, 256 GByte Arbeitsspeicher, 50 GB/s Bandbreite). Die teuerste Variante bietet sich aufgrund der hohen Anzahl an vGPUs und des relativ großen Arbeitsspeichers insbesondere dann an, wenn es umfangreiche Pre- und Post-Processing-Schritte gibt.
Die maximale Ausbaustufe der Multi-GPU-Variante gd4dn.metal (8 NVIDIA GPUs, 96 vGPUs, 100 GB/s Interconnection) ist mit ca. 8 Euro/h dann schon nicht mehr ganz so günstig.
Ich gebe zu: Das waren jetzt sehr, sehr viele Details. Da ein Bild in der Regel mehr sagt als 1000 Worte, habe ich diese Informationen noch einmal als Schaubild zusammengefasst:

(Bild: open knowledge)
Wer es noch detaillierter mag, sollte einen Blick auf die AWS-GPU-Liste von Shashank Prasanna werfen. Shashank hat sich die Mühe gemacht, alle genannten Features und noch einige mehr, in einer Übersicht zusammenzufassen.
Training vs. Inference
Im bisherigen Verlauf des Blogbeitrags habe ich fast ausschließlich über die Eignung der verschiedenen GPU-Instanzen zum Trainieren von ML-Modellen geschrieben. Was aber ist mit der Bereitstellung der trainierten Modelle zwecks Vorhersagen in einer produktiven Umgebung? Macht es Sinn, dort auf die gleichen EC2-Instanzen zurückzugreifen wie im Training? Natürlich wäre dies möglich, würde aber je nach Typ des trainierten ML-Modells und der zur Vorhersage genutzten Daten überproportional hohe Kosten verursachen. Grund dafür sind die unterschiedlichen Anforderungen an das Training eines Modells und dessen Nutzung für Vorhersagen, wie die folgende Abbildung zeigt.
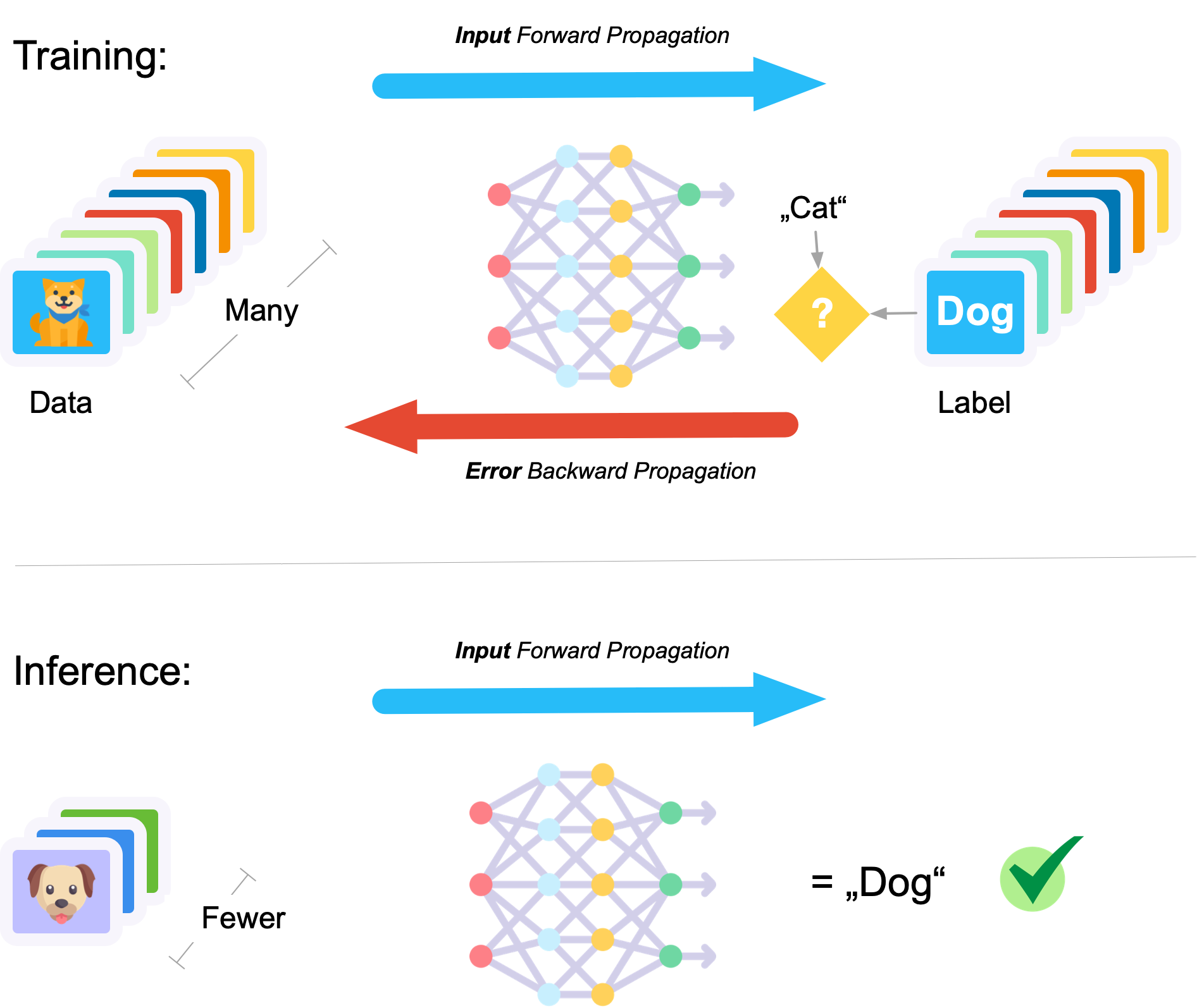
(Bild: open knowledge)
Während des Trainings eines ML-Modells werden in der Regel sehr, sehr viele Daten durch das Modell geschickt (Forward Propagation) und dort für dessen schrittweise Adaption (Backward Propagation) genutzt. Dieser Vorgang wiederholt sich etliche Male. Bei der Vorhersage dagegen, ist die Menge der zu verarbeitenden Daten meist deutlich geringer, dafür ist aber – aus Gründen der User Experience – eine geringe Latenz, also eine möglichst kurze Zeitspanne für die Vorhersage, entscheidend.
Ausschlaggebend für das Erreichen einer geringen Latenz in der Inference sind nicht nur Typ des ML-Modells und die Menge der zu verarbeitenden Daten, sondern auch Aspekte, wie die Möglichkeiten zur Anwendung eigener Operationen auf den jeweiligen EC2-Instanzen, die von den Instanzen unterstützten Deep-Learning-Frameworks oder die zur Laufzeit zur Verfügung stehenden Toolchains.
Hierbei gilt die goldene Regel: Je spezialisierter die Hardware für die Bereitstellung von ML-Modellen, angefangen bei CPUs über GPUs bis hin zu ASICs (Application Specific Integrated Circuits), desto höher zwar deren Leistung, aber desto geringer auch deren Flexibilität.

(Bild: open knowledge)
Inference-Variante 1: GPU-Acceleration
Wie bereits beim Training von ML-Modellen gesehen, bieten GPUs durch ihre Optimierung auf parallele Verarbeitung von Daten einige Vorteile gegenüber CPUs.
GPUs bieten dank ihrer Optimierung auf parallele Verarbeitung von Daten auch in ML-Inference-Szenarien einige Vorteile gegenüber CPUs. Da GPUs allerdings auf Durchsatz optimiert sind, spielen sie ihren Vorteil nur dann wirklich aus, wenn das Modell sehr häufig angesprochen wird oder Batches verarbeitet werden. Ist dies nicht der Fall, läuft die GPU leer und verursacht unnötige Kosten.
Wie weiter oben beschrieben, bieten sich in der AWS-Cloud insbesondere die G4- oder P3-Instanzen für Inference-Szenarien an. G4-Instanzen bieten das beste Preis-Leistungs-Verhältnis, wenn 16 GByte pro Instanz für die Vorhersage ausreichend sind, was für die meisten Modelle der Fall sein sollte. Für sehr große Modelle oder die Verarbeitung von sehr großen Bild- oder anderen Daten, kann alternativ auf die etwas teureren P3-Instanzen mit 32 GByte zurückgegriffen werden.
Nun sind GPUs aber leider nicht in der Lage, beliebige Operationen out-of-the-box zu beschleunigen. Wird eine Operation benötigt, die nicht direkt unterstützt wird, kann diese via NVIDIAs CUDA Programing Model in Form eines Custom Layers des ML-Modells zur Verfügung gestellt werden.

(Bild: open knowledge)
NVIDIA bietet dafür speziell auf die Operationen neuronaler Netze zugeschnittene Libraries an, die von Frameworks wie TensorFlow, PyTorch oder MXNet transparent genutzt werden. Für die Optimierung des eigenen Modells ist somit (fast) kein manuelles Eingreifen notwendig. Diese Flexibilität zur individuellen Erweiterung bei gleichzeitig sehr hoher Performance ist einer der großen Vorteile der GPUs.
Sollte die so erzielbare Performance immer noch nicht ausreichend sein, lässt sich das trainierte Modell durch den TensorRT Model Compiler noch weiter optimieren. Aber Achtung; dies kann zu einer geringfügigen Verringerung der Genauigkeit in den Vorhersagen führen, da unter der Haube je nach Optimierung mit einer geringeren Genauigkeit (FP32, FP16 oder FP8) gerechnet wird.
Auch wenn GPUs eine vielversprechende Möglichkeit zur Bereitstellung von ML-Modellen zwecks Vorhersage darstellen, sind sie nicht in allen Fällen optimal. Je nach Modell und Anfragemuster können entweder Latenzen und/oder Kosten überproportional hoch sein und sich das zugrundeliegende Geschäftsmodell somit gegebenenfalls nicht mehr rechnen. Wie sieht in einem solchen Fall die Alternative aus?
Inference-Variante 2: AWS Inferentia
Bei AWS Inferentia handelt es sich um einen speziell für Vorhersagen mittels ML-Modell designten Chip. Der Chip ist vom Design her auf hohen Durchsatz und geringe Latenz ausgelegt. Mit dieser sehr speziellen Ausrichtung auf Inference-Optimierung fällt der Chip in die Kategorie der Application Specific Integrated Circuits (ASICs). Diese Chips haben genau eine Aufgabe, und sind für eben diese optimiert. Im Gegenzug sind sie deutlich weniger flexibel im Vergleich zu GPUs oder CPUs, was sich bei der Unterstützung von Custom Layern negativ auswirken kann.
AWS bietet seine Inferentia-Instanz mittlerweile in der zweiten Generation an (Inf1, Inf2). Jeder Inferentia-Chip verfügt über mehrere NeuronCores – eine Art spezialisierter Matrix-Multiplizierer inklusive dafür optimiertem Speicher und großem On-Chip-Cache.
Um die Vorteile der Inferentia-Instanzen nutzen zu können, sollte das eigene ML-Modell entweder mit MXNet, TensorFlow oder PyTorch trainiert oder alternativ in das ONNX-Format konvertiert worden sein. Ist beides nicht der Fall, sollte es maßgeblich Operationen verwenden, die vom AWS Neuron SDK unterstützt werden, da ansonsten die entsprechenden Operationen nicht wie gewünscht auf dem spezialisierten Chip, sondern auf einer CPU ausgeführt werden würden.

(Bild: open knowledge)
Ist das eigene Modell und die Workload für AWS Inferentia geeignet, kann bei vorgegebener Latenz ein deutlich höherer Durchsatz bei gleichzeitig geringeren Kosten im Vergleich zu GPU und CPU erreicht werden. Ein guter Benchmark findet sich in dem AWS Blogbeitrag von Fabio Nonato de Paula and Mahadevan Balasubramaniam.
Getreu dem Motto "eat your own dog food" lässt AWS mittlerweile einen Großteil seiner Alexa-Anwendungen auf Inferentia-Instanzen laufen.
Inference-Variante 3: Elastic Inference
Mit seinem Elastic-Inference-Modell bietet AWS eine weitere kostengünstige Alternative für ML-Inference-Szenarien, in denen die Verwendung einer CPU zu langsam wäre, eine dedizierte GPU-Instanz dagegen aber zu hohe Kosten verursachen würde.
Die Idee der Elastic-Inference-Instanz besteht darin, dass lediglich eine klassische EC2-CPU-Instanz, wie zum Beispiel eine C5-Instanz, provisioniert wird und diese bei Bedarf Aufrufe über das Netzwerk an eine von sechs verschiedenen GPU-Instanz-Typen weiterleitet. Kosten für die GPU-Instanzen fallen dabei nur für den Zeitraum des Aufrufs und der anschließenden Verarbeitung an. AWS Elastic Inference kann somit als eine Art GPU on-demand verstanden werden. Die verschiedenen GPU-Instanzen variieren von 1 bis 4 TFLOPS und 1 bis 8 GByte Speicher.

(Bild: open knowledge)
Genau wie AWS Inferentia unterstützt auch AWS Elastic Inference Modelle, die mit MXNet, TensorFlow oder PyTorch trainiert oder in das ONNX Format konvertiert worden sind.
Der Einsatz von AWS Elastic Inference macht immer dann Sinn, wenn eine dediziert provisionierte GPU-Instanz nicht ausgelastet und somit zu teuer wäre oder die Anforderungen an die GPU stark variieren, was zum Beispiel bei der parallelen Bereitstellung mehrerer Modelle der Fall wäre.
Da die GPUs nicht direkt angesprochen werden, sondern über den Umweg der CPU via Netzwerk, erhöht sich natürlich die Latenz im Vergleich zu einer rein GPU-basierten Lösung ein wenig. Liegt diese aber aus Sicht der Customer Experience noch im vertretbaren Rahmen, lässt sich mit AWS Elastic Inference sehr viel Geld sparen.
AWS GPU Cheat Sheet
Machine-Learning-Workloads stellen besondere Ansprüche an die Hardware. Welche dedizierte Hardware am Ende am besten geeignet ist, entscheiden das zugrundeliegende Modell, die zu verarbeitenden Daten und etliche weitere Faktoren. Eine One-size-fits-all-Lösung gibt es leider nicht.
AWS bietet ein breites Portfolio an speziell für ML-Szenarien optimierten EC2-Instanzen an und differenziert dabei bewusst zwischen dem rechenintensiven Training von Modellen und Inference, also Vorhersage mittels trainierter Modelle. Ein vollständige Übersicht findet sich unter Amazon EC2 / Accelerated Computing.
Da die Auswahl der richtigen EC-Instanz nicht immer ganz trivial ist, habe ich abschließend noch einmal die wichtigsten Fakten zusammengestellt und als AWS GPU Cheat Sheet aufbereitet.

(Bild: open knowledge)
EC2-Instanzen für das Training von ML-Modellen:
Höchste Performance und maximale Parallelisierung von Modell und/oder Daten für das Training großer bis sehr großer Modelle: P5-Instanz p5.48xlarge auf Basis von 8 Nvidia H100 GPUs à 80 GB Speicher und NVSwitch GPU Interconnection (900GB/s).
Bestes Preis-Leistungs-Verhältnis bei gleichzeitig guter Parallelisierung von Modell und/oder Daten für das Training mittlerer bis großer Modelle: P3-Instanz p3.8xlarge, p3.16xlarge und p3dn.24xlarge auf Basis von 4 bis 8 NVIDIA V100 GPUs à 16 bis 32 GByte Speicher, 32 bis 96 vGPUs und NVLink Interconnection der zweiten Generation (300 GB/s).
Beste Performance für das Training mittlerer Modelle auf einer Single-GPU: P3-Instanz p3d.2xlarge auf Basis von NVIDIA V100 GPU mit 16 GByte Speicher und 8 vGPUs.
Bestes Preis-Leistungs-Verhältnis für das Training mittlerer Modelle auf einer Single-GPU: G5-Instanz g5.xlarge auf Basis von NVIDIA A10G GPU mit 24 GByte Speicher und 4 vGPUs. Alternativ G4-Instanz g4dn.xlarge auf Basis von NVIDIA T4 GPU mit 16 GByte Speicher.
EC2-Instanzen für die Bereitstellung von trainierten ML-Modellen:
G4- oder P3-Instanzen für ML-Inference-Szenarien mit gleichmäßig hoher Auslastung bei adäquater Latenz und hoher Flexibilität.
AWS Elastic Inference mit vorgeschalteter EC2-CPU-Instanz und on-demand GPU-Instanzen für ML-Inference-Szenarien mit ungleichmäßig hoher Auslastung bei adäquater Latenz und adäquater Flexibilität.
AWS Inferentia (inf1 oder inf2) für ML-Inference-Szenarien mit gleichmäßiger Auslastung bei optimierter Latenz und adäquater Flexibilität.
Superlative in Kooperation mit Nvidia
Welch enorme wirtschaftliche Relevanz der Bereich Accelerated Computing und die damit einhergehenden EC2-Instanzen für Workload aus den Bereichen künstliche Intelligenz und Machine Learning für AWS hat, zeigen die vielen Superlative in der Zusammenarbeit zwischen AWS und Nvidia.
Allen voran glänzt der jüngst aufgesetzte UltraCluster der zweiten Generation, mit dem AWS-Kunden bis zu 20.000 P5-Instanzen parallel nutzen können. Ein Ende scheint noch lange nicht in Sicht zu sein. Es bleibt spannend, wie es in den kommenden Jahren weitergeht.
In diesem Sinne "stay connected!".
(rme)
