

Objekte speichern und bearbeiten mit Manta
Fleißiger Speicherdienst
Serverless ist einer der großen Trends in der IT. Während Anwender bisher virtuelle Server je nach Bedarf gemietet haben, soll heute der Aufwand gering gehalten werden. Nur die Funktion, die eine Software auf einem Managed Server bereitstellt, soll nach Bedarf genutzt und bezahlt werden.
Den Begriff „serverless“ prägte Amazon 2014 mit seinem Dienst AWS Lambda. Es gab allerdings schon vorher Plattformen, die eine solche serverlose Softwarenutzung erlaubten. Eine davon heißt Manta. Sie wurde 2013 von der Firma Joyent vorgestellt und 2015 zusammen mit deren Cloud-Management-Plattform Triton (damals noch SmartDatacenter) unter der Mozilla Public License 2.0 freigegeben. Bei seiner Vorstellung 2013 sahen die meisten Beobachter Manta vermutlich als Alternative zu Amazons Object-Storage S3. Etwas ihrer Zeit voraus waren die integrierten Funktionen und Jobs, die Manta zu einer „serverless“ Plattform machten – obwohl das damals noch niemand so nannte.
Deshalb eignet Manta sich gut für einen Blick hinter die Kulissen eines Serverless-Angebots. Denn natürlich lassen sich die Server (weder die virtuellen noch die physikalischen) nicht einfach aus der Gleichung herauskürzen – es muss sich nur jemand anderes um deren Betrieb kümmern. Manta setzt auf die Cloud-Verwaltung Triton [1]. Während Triton jedoch recht gut ohne Manta auskommen kann, lässt sich Manta nicht ohne Triton aufbauen. Grundlage bildet das an OpenSolaris angelehnte Betriebssystem SmartOS. Es beherrscht die von Solaris bekannten Zonen – Anwendungen darin sind vom Rest des Systems abgeschottet und haben nur auf eingeschränkte Ressourcen Zugriff wie bei Containern.
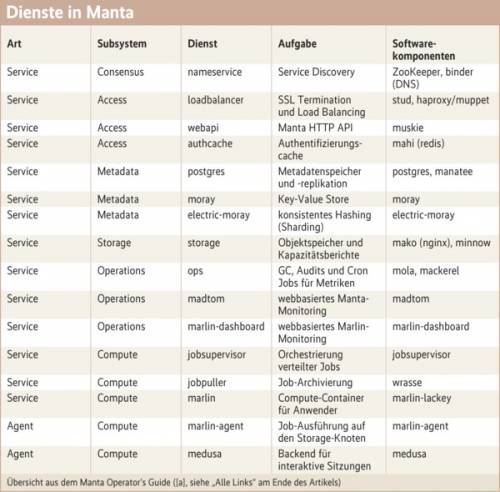
Wie Triton besteht Manta aus einer Reihe von Diensten (siehe Tabelle). Die meisten davon sind stateless und damit problemlos skalierbar. Das Speichern dauerhaft benötigter Daten übernimmt ein (schon von Triton bekannter) Postgres-Cluster mit vorgeschaltetem Key-Value Store.
Uploads weiterverarbeiten
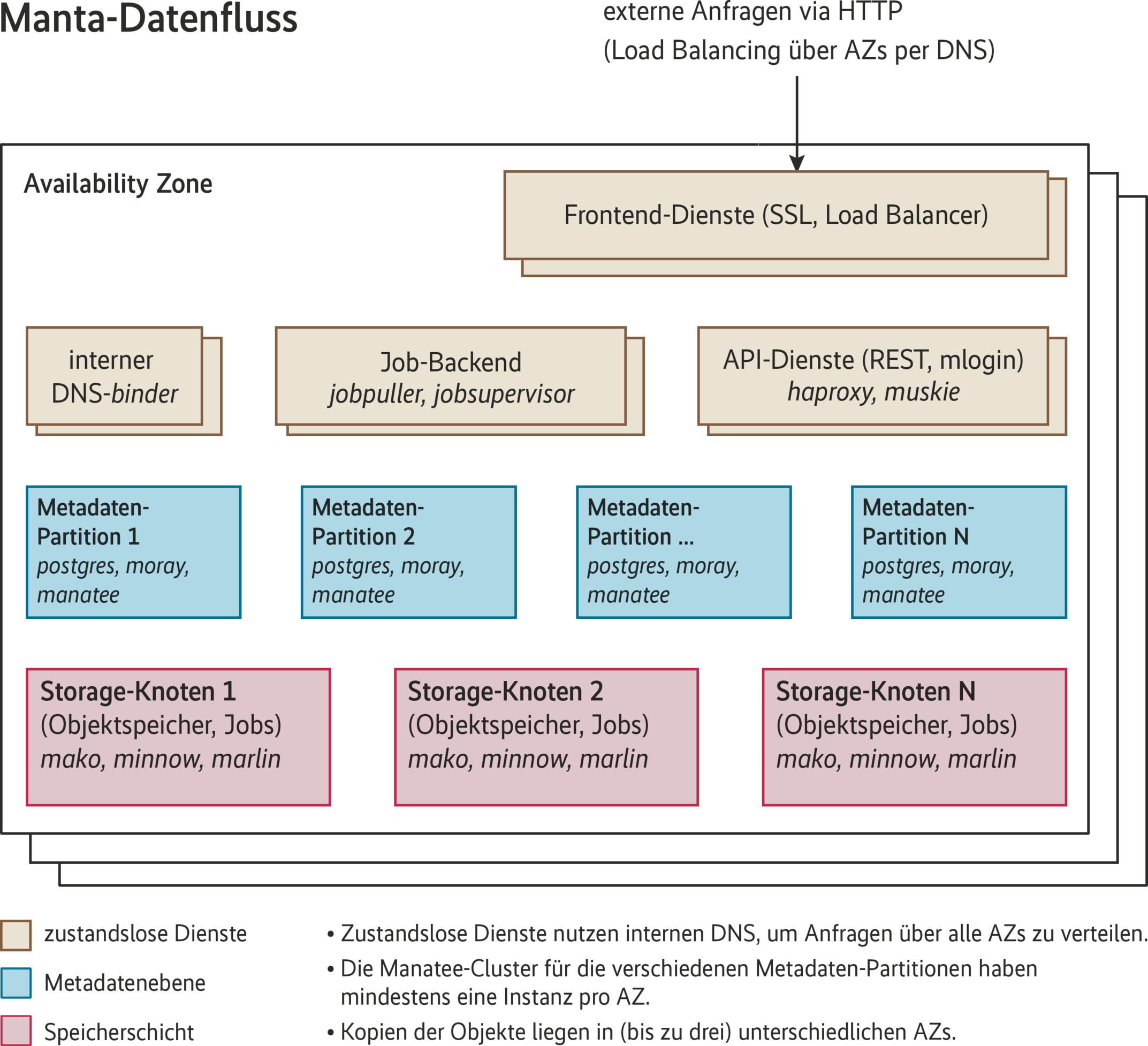
Nutzer laden über Load Balancer Objekte in Manta. Dort werden diese als Flat File im Dateisystem (ZFS) der storage-Zonen gespeichert. Mit „Jobs“ lassen sich die Objekte anschließend bearbeiten. Jeder Manta-Job startet in einem separaten Container, also in einer eigenen SmartOS-Zone. In diese wird das Objekt, das der Job bearbeiten soll, eingebunden. Dafür verwendet Manta hyperlofs ([b], siehe „Alle Links“ am Ende des Artikels).
Diese speziellen SmartOS-Zonen heißen Marlin. Sie werden auf jedem Storage-Knoten erzeugt und vorgehalten, um Manta-Jobs abzuarbeiten, und enthalten ein reichhaltiges Softwareangebot [c]: Node.js, Python, Ruby, Perl, PHP, Go, Java, diverse GCC-Versionen, verschiedene Pakete zur Text-, Bild- und Videokonvertierung und Clients für MySQL- und Postgres-Datenbanken. Derzeit werden etwa 33 GByte Software mitgeliefert.
Zusätzlich kann man eigene Software als sogenanntes Manta-Asset hochladen und ausführen. Auch vorhandene Software lässt sich erweitern. So können Nutzer spezielle Bibliotheken für R in Manta speichern [d].
Das Dateisystem der Marlin-Zonen ist jeweils der Snapshot eines Klons des ursprünglichen Marlin-Image. Ist ein Job abgearbeitet, stellt ein zfs rollback den ursprünglichen Zustand wieder her (alle geänderten Daten gehen verloren), und die Zone ist für den nächsten Job bereit. Auf diese Weise wird selbst bei einer großen Anzahl von Marlin-Zonen nur ein Image pro Node benötigt und tatsächlich nur Platz für hochgeladene Assets oder Ergebnisse von Manta-Jobs belegt.
Robustes Speichern mit ZFS
Manta verwendet keine nachträgliche Datenreplikation, um die Verfügbarkeit der Objekte im Storage zu erhöhen, sondern stellt lediglich PUT- und GET-Operationen zur Verfügung – soll ein Objekt aktualisiert werden, geschieht dies durch eine erneute PUT-Operation mit dem gleichen Namen. Von hochgeladenen Objekten erzeugt Manta automatisch mindestens zwei Kopien. Benutzer können beim Hochladen für individuelle Objekte die Anzahl der Kopien festlegen, die auf verschiedenen Storage-Nodes abgelegt werden. Erstreckt sich die Manta-Installation etwa über drei Rechenzentren, werden die ersten drei Kopien über alle drei verteilt.
Innerhalb der Rechenzentren sorgen die Load Balancer für eine günstige Verteilung der Last auf die Storage-Nodes. Manta meldet erst dann ein erfolgreiches Speichern, wenn sowohl die Kopien im Dateisystem als auch die Metadaten im Postgres-Cluster abgelegt sind. Damit sind Manta-Operationen „strongly consistent“ und nicht „eventual consistent“ wie manche Operationen anderer Object Stores.
Pro Region sollte Manta mit drei Availability Zones (AZ) aufgebaut werden. Dabei sollten die AZs natürlich keine Komponenten von anderen AZs derselben Region mitverwenden. So aufgebaut sollte Manta alle Netzwerkpartitionierungen zwischen AZs bis zum Verlust einer kompletten AZ überleben können.
Hinsichtlich der Datensicherheit verlässt sich Manta komplett auf ZFS (RAID-Z2 mit Hot Spares), um die einzelnen Nodes so ausfallsicher wie möglich zu machen. Fault Tolerance in Manta beschreibt die zugrunde liegenden Überlegungen und Entscheidungen im Detail [e].
Leider läuft die Installation von Manta nicht automatisiert wie die von Triton, sodass etwas mehr Handarbeit und etwas mehr Verständnis erforderlich ist. Der Aufbau einer produktiven Manta-Installation erfordert viel Überlegung und Planung. Im Operator’s Guide gibt es dafür ein eigenes Kapitel: Die Zahl der zu verwendenden Rechenzentren, die Größe der Umgebung und die damit verbundene Anzahl der Datenbank-Cluster für Metadaten, die Anzahl der Storage-Nodes und das Layout der verschiedenen Zonen über die beteiligten Nodes sind Punkte, die dabei eine große Rolle spielen.