

Multithreading in C++17 und C++20
Eine Aufgabe für sich
Bereits seit C++11 stellt die Programmiersprache Funktionen für das Multithreading zur Verfügung. Die sind allerdings alles andere als intuitiv zu verwenden. Die neuen Versionen des Standards sollen weitere Abstraktionen einführen und damit die Entwicklung sicherer Multithreaded-Anwendungen deutlich erleichtern.
Eine, wenn nicht die Herausforderung für eine moderne Programmiersprache ist es, die Power, die in jedem modernen Rechner steckt, auf sichere Weise herauszukitzeln. Das ist mit bisherigen Multithreading-Strategien für den normalsterblichen Programmierer nicht möglich. Daher bietet C++17 und vor allem C++20 weitgehende Abstraktionen an, die die bisherigen Konzepte atomare Variablen, Threads, Bedingungsvariablen oder Mutexe und Locks auf die Stufe einer Assemblersprache für Multithreading degradieren.
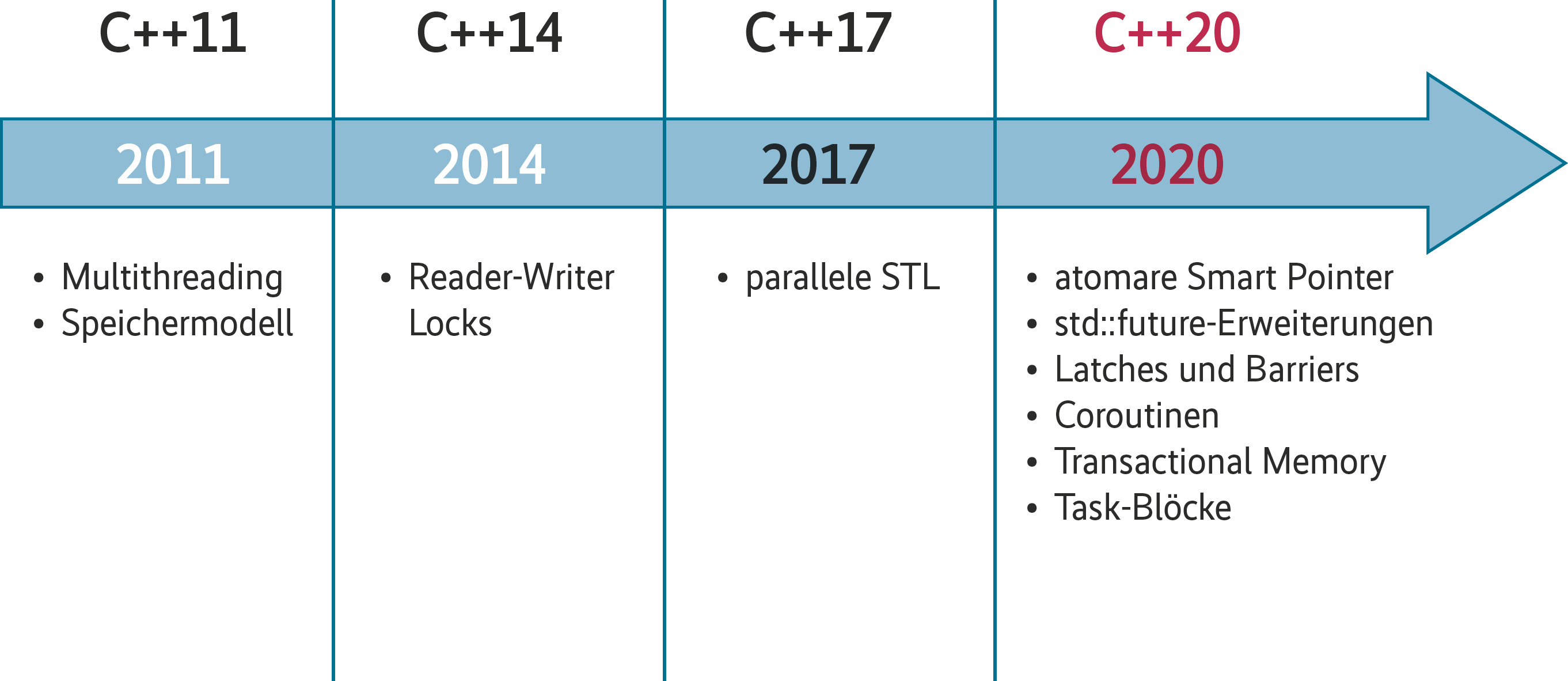
Der Zeitstrahl in Abbildung 1 zeigt, welche Möglichkeiten für Multithreading die bisherigen Standards gebracht haben und welche von C++17 und C++20 zu erwarten sind. Mit der parallelen Standard Template Library (STL) in C++17 und insbesondere atomaren Smart Pointern, den std::future-Erweiterungen, Latches und Barriers, Coroutinen, Transactional Memory und Task-Blöcken in C++20 wird die Sprache um viele neue Konzepte erweitert, die alle Inhalt dieses Artikels sind.
Parallele Standard Template Library in C++17
Die Standard Template Library enthält gut 100 Algorithmen für das Suchen, Zählen, Manipulieren von Bereichen und deren Elemente. Mit C++17 wurden 69 der Algorithmen überladen und neue hinzugefügt. Diese überladenen und neuen Algorithmen kann man mit einer sogenannten Execution Policy aufrufen und damit spezifizieren, wie eine Anwendung den Algorithmus ausführt. Der iX-Artikel „In Erwartung“ [1] gab bereits einen Einblick in die STL. Hier folgen weitere Details.
Listing 1: Parallelisierter Quicksort-Algorithmus mit statischer Execution Policy
1 template <class ForwardIt> 2 void quicksort(ForwardIt first, ForwardIt last){ 3 if(first == last) return; 4 auto pivot = *std::next(first, std::distance(first,last)/2); 5 ForwardIt middle1 = std::partition(std::parallel::par, first, last, 6 [pivot](const auto& em){ return em < pivot; }); 7 ForwardIt middle2 = std::partition(std::parallel::par, middle1, last, 8 [pivot](const auto& em){ return !(pivot < em); }); 9 quicksort(first, middle1); 10 quicksort(middle2, last); 11 }
Ob ein Algorithmus sequenziell (std::parallel::seq), parallel (std::parallel::par) oder parallel und vektorisierend (std::parallel::unseq) ausgeführt wird, legt die Execution Policy fest. Diese Entscheidung kann im Sourcecode (statisch) oder zur Laufzeit (dynamisch) getroffen werden. Die Erzeugung eines Thread ist eine teure Operation. Daher ergibt es keinen Sinn, einen Container mit wenigen Elementen mit einer parallelen Strategie oder parallel und vektorisierend zu sortieren. Der Verwaltungsaufwand fräße den Vorteil der Parallelisierung mehr als auf. Noch drastischer können die Nebenwirkungen sein, wenn ein „Teile-und-herrsche-Algorithmus“ (Divide and Conquer Algorithm [a]) zum Einsatz kommt. Ein klassisches Beispiel für ein solches Vorgehen ist der Quicksort-Algorithmus in Listing 1. (Zu Ressourcen im Web siehe „Alle Links“ am Ende des Artikels.)
Listing 2: Parallelisierter Quicksort-Algorithmus mit dynamischer Execution Policy
1 std::size_t threshold= ...; // some value 2 3 template <class ForwardIt> 4 void quicksort(ForwardIt first, ForwardIt last){ 5 if(first == last) return; 6 std::size_t distance= std::distance(first,last); 7 auto pivot = *std::next(first, distance/2); 8 9 std::parallel::execution_policy exec_pol= std::parallel::par; 10 if ( distance < threshold ) exec_pol= std::parallel_execution::seq; 11 12 ForwardIt middle1 = std::partition(exec_pol, first, last, 13 [pivot](const auto& em){ return em < pivot; }); 14 ForwardIt middle2 = std::partition(exec_pol, middle1, last, 15 [pivot](const auto& em){ return !(pivot < em); }); 16 quicksort(first, middle1); 17 quicksort(middle2, last); 18 }
Jeder Aufruf von std::partition in Zeile 5 und 7 findet parallel statt. Hier ist die Gefahr groß, dass die Anzahl der gestarteten Threads deutlich zu hoch für das System wird. Umso besser, dass es in C++17 auch eine dynamische Execution Policy gibt. Listing 2 stellt die ressourcenschonende Alternative vor.

Listing 3: Die acht neuen Algorithmen der STL
std::for_each std::for_each_n std::exclusive_scan std::inclusive_scan std::transform_exclusive_scan std::transform_inclusive_scan std::parallel::reduce std::parallel::transform_reduce
In Zeile 12 und 14 kommt die dynamische Execution Policy zum Einsatz. Per Default wird Quicksort parallel ausgeführt (Zeile 9). Falls aber die Länge des zu sortierenden Bereichs kleiner als eine vorgegebene Schwelle threshold (Zeile 1) ist, läuft Quicksort sequenziell (Zeile 10). Abbildung 2 zeigt die Algorithmen, die eine parallele oder parallele und vektorisierende Execution Policy unterstützen. Dazu kommen acht neue Algorithmen (Listing 3).
Besonders interessant ist std::parallel::transform_reduce. Die aus Haskell bekannte Funktion map entspricht in C++ der Funktion std::transform. Wenn das kein Wink mit dem Zaunpfahl ist: Denn wird in std::parallel::transform_reduce der Begriff transform durch map ersetzt, hieße der Algorithmus std::parallel::map_reduce. MapReduce [b] ist das weltweit eingesetzte parallele Framework, das in seiner ersten Phase jeden Wert auf einen neuen Wert abbildet und in seiner zweiten Phase diese neuen Werte auf das Ergebnis reduziert.
Listing 4: MapReduce in C++17
1 std::vector<std::string> str{"Only","for","testing","purpose"}; 2 3 std::size_t result= std::parallel::transform_reduce(std::parallel::par, 4 str.begin(), str.end(), 5 [](std::string s){ return s.length(); }, 6 0, [](std::size_t a, std::size_t b){ return a + b; }); 7 8 std::cout << result << std::endl; // 21
Dieser zweistufige Algorithmus lässt sich jetzt direkt in C++17 anwenden. So bildet in Listing 4 die Transform-Phase jedes Wort auf seine Länge ab und die Reduce-Phase summiert die Länge aller Wörter. Startwert ist die Null und das Ergebnis die Summe aller Wörter eines Vektors.
Das war es schon mit der Gegenwart. Nun geht es drei Jahre in die Zukunft.
Atomare Smart Pointer mit C++20
C++20 wird atomare Smart Pointer erhalten. Genau genommen wird es einen std::atomic_shared_ptr und einen std::atomic_weak_ptr geben. Fragt sich, warum, da std::shared_ptr und std::weak_ptr doch schon Thread-sicher sind. Das stimmt allerdings nur bedingt.
std::shared_ptr besitzt zwar eine klar definierte Multithreading-Semantik, das heißt aber nicht zwingend, dass ein Programmierer diese Semantik kennt und richtig einsetzt. Aus der Multithreading-Perspektive betrachtet, ist std::shared_ptr eine Datenstruktur, die nach Problemen in Multithreading-Programmen schreit. Denn es handelt sich bei solchen Pointern um geteilte, veränderliche Daten. Damit sind sie ideale Kandidaten für kritische Wettläufe (Race Conditions [c]) und undefiniertes Programmverhalten. Andererseits gilt die einfache Richtlinie in modernem C++: Fasse Speicher nicht direkt an. Daher sollen Smart Pointer in Multithreading-Programmen eingesetzt werden.
Das eigentliche Problem ist aber, dass Smart Pointer nur halb Thread-sicher sind. Ein Smart Pointer wie std::shared_ptr besteht aus einem Kontrollblock und seiner Ressource. Der Kontrollblock ist Thread-sicher, die Ressource jedoch nicht. Das heißt, dass das Ändern des Referenzzählers eine atomare Operation ist und die Ressource genau einmal freigegeben wird. Mehr Garantie gibt der std::shared_ptr nicht. Daher nehmen diese Datenstrukturen eine Sonderstellung ein. Sie sind die einzigen nicht atomaren Datentypen, für die es atomare Operationen gibt. Die genaue Übersicht liefert cppreference.com [d].
Smart Pointer sind nur halb Thread-sicher
Man könnte jetzt meinen, es sei ein Leichtes, einen per Referenz gebundenen std::shared_ptr Thread-sicher zu modifizieren. Leider stimmt das nicht, denn bei jeder Operation auf einem Smart Pointer ist es notwendig, atomare Operationen zu verwenden. Der Proposal N4162 [e] für atomare Smart Pointer bringt die Unzulänglichkeiten der bisherigen Implementierung direkt auf den Punkt. Sie werden an den drei Punkten Konsistenz (Consistency), Korrektheit (Correctness) und Performanz (Performance) festgemacht:
– Konsistenz: Die atomaren Operationen für den std::shared_ptr sind die einzigen atomaren Operationen, die nicht explizit durch einen atomaren Typ angeboten werden.
– Korrektheit: Die Verwendung der freien atomaren Operationen ist fehleranfällig, da sie auf der Disziplin des Anwenders basiert. Ist hingegen der Smart Pointer ein atomarer Datentyp, unterbindet der Compiler einen falschen Einsatz.
– Performanz: std::atomic_shared_ptr und std::atomic_weak_ptr haben einen deutlichen Vorteil gegenüber den freien atomic_*-Funktionen. Sie sind für den speziellen Anwendungsfall Multithreading konzipiert und optimiert.
Die Details lassen sich im Proposal nachlesen [e].
std::future-Erweiterungen für bessere Tasks
Ähnlich wie Smart Pointer waren Futures eine der großen Neuerungen in C++11. Tasks in der Form von Promises und Futures haben einen ambivalenten Ruf. (Zu den Vorteilen von Tasks siehe den Kasten und cppreference.com [f].) Zum einen sind sie deutlich leichter und weniger fehleranfällig zu verwenden als Threads oder Bedingungsvariablen, zum anderen weisen sie eine große Unzulänglichkeit auf. Man kann sie nicht komponieren (verketten). Damit räumt C++20 auf.
Listing 5: Ein Future nach dem anderen
1 #include <future> 2 using namespace std; 3 int main() { 4 5 future<int> f1 = async([]() { return 123; }); 6 future<string> f2 = f1.then([](future<int> f) { 7 return to_string(f.get()); // here .get() wont block 8 }); 9 10 auto myResult= f2.get(); 11 12 }
Der kommende Standard erweitert std::future fut um neue Methoden. So kann fut.is_ready abfragen, ob ein gemeinsamer Zustand (Shared State) vorliegt, oder fut.then kann Futures komponieren. Letzteres zeigt Listing 5.
Es besteht ein feiner Unterschied zwischen dem to_string(f.get()) in Zeile 7 und dem f2.get()-Aufruf in Zeile 10. Wie im Code angedeutet, ist der erste Aufruf nicht blockierend und asynchron, der zweite Aufruf hingegen ist blockierend und synchron. Der f2.get()f-Aufruf wartet, bis das Ergebnis der verketteten Futures zur Verfügung steht. Diese Aussage trifft nicht nur auf Future-Kompositionen wie f1.then(…).then(…).then(…).then(…) zu, sondern auf alle Zusammensetzungen erweiterter Futures. Der finale f2.get() Aufruf ist blockierend.
Listing 6: std::make_ready_future
future<int> compute(int x) {
if (x < 0) return make_ready_future<int>(-1);
if (x == 0) return make_ready_future<int>(0);
future<int> f1 = async([]() { return do_work(x); });
return f1;
}
C++20 erhält vier weitere Funktionen, die das Erzeugen besonderer Futures erlauben: std::make_ready_future, std::make_exceptional_future, std::when_all und std::when_any. Die Funktionen std::make_ready_future und std::make_exceptional_future erzeugen einen Future, der sofort bereit ist. Im ersten Fall hat er einen Wert, im zweiten Fall eine Ausnahme. Was sich am Anfang seltsam anhört, ergibt durchaus Sinn. Das Erzeugen eines bereiten Future setzt mit C++11 einen Promise voraus. Dies ist selbst dann notwendig, wenn der Wert des gemeinsamen Zustands sofort zur Verfügung steht.
Listing 7: std::when_any
1 vector<future<int>> v{ .... }; 2 auto future_any = when_any(v.begin(), v.end()); 3 4 when_any_result<vector<future<int>>> result= future_any.get(); 5 6 future<int>& ready_future = result.futures[result.index]; 7 8 auto myResult= ready_future.get();
So muss in Listing 6 das Ergebnis nur aufwendig mithilfe eines Promise berechnet werden, wenn (x > 0) gilt. Nur als Hinweis: Die beiden Funktionen sind das Pendant zur return-Funktion in einer Monade [2]. std::when_all und std::when_any geben einen Future zurück, der automatisch startet. Im Falle von when_any startet der Future, wenn einer seiner Vorgänger seine Arbeit vollzogen hat. Dies zeigt Listing 7.