

Machine Learning mit Apache Spark
Lernförderung
Mit Apache Spark steht ein mächtiges und vielseitiges Big-Data-Framework bereit. Es bringt zudem eine Bibliothek für maschinelles Lernen mit, die nicht nur Lernverfahren, sondern auch Tools für Datenaufbereitung und Tuning enthält.
Machine Learning hält in immer mehr Bereiche Einzug, alle namhaften IT-Konzerne wie Google (TensorFlow), Apple, Amazon, Microsoft (Azure ML Studio) und IBM (Watson) entwickeln Anwendungen, die auf Machine-Learning-Verfahren basieren. Ein bekannter Vertreter aus dem Bereich ist Amazons Mechanismus „Kunden, die diesen Artikel gekauft haben, kauften auch“. Dabei ist längst nicht jeder Anwendung auf den ersten Blick anzusehen, dass Machine Learning im Einsatz ist, aber ohne Verfahren aus diesem Bereich wären viele in unseren heutigen Alltag integrierte Assistenzsysteme wie Spracherkennung oder Textergänzung nicht denkbar.
Machine Learning subsummiert alle Verfahren, die es Maschinen erlauben, auf Basis vorhandener Daten Modelle zu entwickeln. Auf diesen Modellen aufbauend können beispielsweise Muster in Daten erkannt, Daten klassifiziert und Vorhersagen getroffen werden.
Wesentliche Konzepte von Apache Spark, wie Resilient Distributed Datasets (RDDs), DataFrames und Spark SQL, wurden in iX 3/2017 [1] vorgestellt. Dieser zweite Teil der Spark-Einführung behandelt die Machine-Learning-Funktionen des Frameworks. Spark MLlib, die Machine Learning Library von Spark, umfasst verschiedene Verfahren aus den Bereichen Klassifikation und Regression, Clustering und Collaborative Filtering (zur Dokumentation siehe „Alle Links“ am Artikelende). Neben den Machine-Learning-Verfahren stellt Spark MLlib (oder kurz Spark ML) auch Mechanismen für die Datenaufbereitung (Extraktion und Transformation von Features) und für die Auswahl und das Tuning von Modellen (Model Selection and Tuning) zur Verfügung. Der Unterschied zu anderen ML-Bibliotheken wie scikit-learn liegt vor allem in der Skalierbarkeit: Spark arbeitet verteilt im Cluster und kann somit auch für sehr große Datenmengen eingesetzt werden.
Vor Version 2.0 des Spark-Frameworks existierten mit spark.mllib und spark.ml zwei Bibliotheken für Machine Learning gleichberechtigt nebeneinander. Bei spark.mllib ist das RDD die zentrale Datenstruktur, während spark.ml auf DataFrames basiert. In Version 2.0 wurde spark.mllib in den Wartungsmodus versetzt. Mit dem avisierten Erreichen der Feature-Parität von spark.ml und spark.mllib in der Version 2.2 wird spark.mllib zum Auslaufmodell und voraussichtlich in Version 3.0 komplett aus dem Framework entfernt. Dieser Artikel bezieht sich daher auf spark.ml. Die Codebeispiele sind in Scala geschrieben – der Programmiersprache, in der Spark entwickelt wurde. Die Aufrufe in Python und Java sind aber bis auf Abweichungen, die durch die Sprachsyntax begründet sind, identisch.
Maschinelles Lernen als Prozess
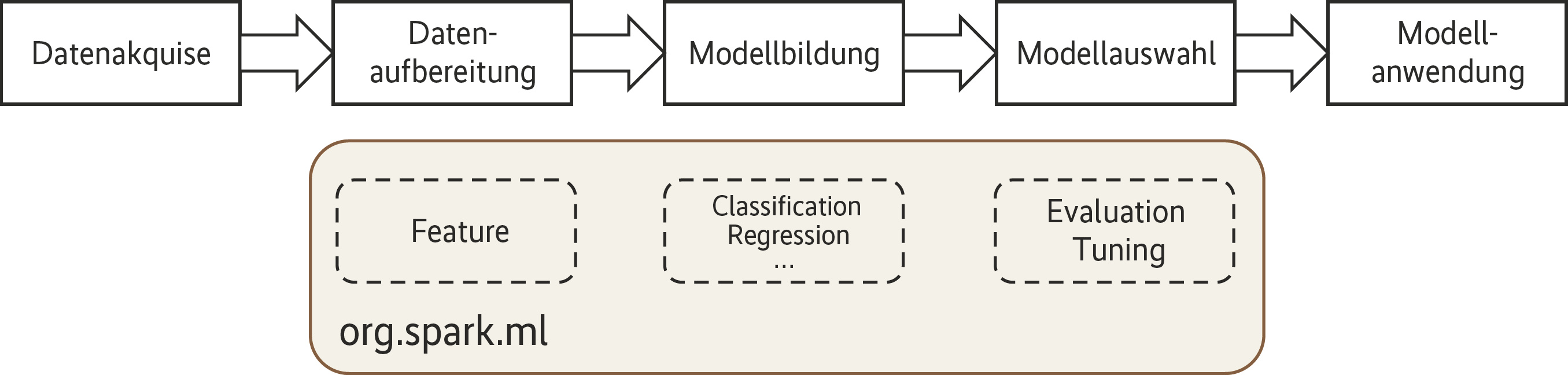
Machine Learning folgt im Wesentlichen den Prozessschritten in Abbildung 1. Den Anfang bilden im Rahmen der Datenakquise die Auswahl und das Sammeln relevanter Daten, die in Zusammenhang mit einer Problemstellung stehen. Im zweiten Schritt müssen die gesammelten Daten so aufbereitet werden, dass sie als Eingabe für die Machine-Learning-Algorithmen verwendet werden können. Diese Vorbereitung der Attribute (Features) bezeichnet man als Feature Engineering, mit den Teilbereichen Feature Extraction (vor allem bei Textdaten), Feature Transformation (Nullwertbehandlung, Diskretisierung, Normalisierung) und Feature Selection (Auswahl relevanter Daten). Dieser Prozessschritt ist zusätzlich zumeist iterativ: Die Datenaufbereitung findet wiederholt statt, bis die jeweils gebildeten Modelle die gewünschte Qualität aufweisen. Hierfür ist insbesondere auch Expertenwissen aus der jeweiligen Domäne gefragt, für die eine Machine-Learning-Anwendung entwickelt werden soll.
Im Schritt der Modellbildung kommen nun die zur Verfügung stehenden Verfahren unter anderem aus den Bereichen Klassifikation und Regression zur Anwendung.
Die Güte der so gebildeten Modelle wird mit Evaluatoren bewertet, die je nach Verfahren unterschiedliche Bewertungskennzahlen verwenden. Ein typisches Gütemaß bei Klassifikationsverfahren ist die Accuracy, der Anteil korrekt klassifizierter Daten. Um diese ermitteln zu können, unterteilt man die Ausgangsdaten vor der Modellbildung in Trainings- und Testdaten. Das Modell wird basierend auf Trainingsdaten gebildet und dann an den Testdaten evaluiert. Durch die Veränderung der Verfahrensparameter (Hyperparameter-Tuning) oder den Einsatz anderer Verfahren kann anschließend versucht werden, bessere Modelle zu finden.
Das auf diese Art gewonnene Modell wird in die eigentliche Applikation eingebunden und dort angewendet, etwa zur Ermittlung eines Risiko-Scores oder zur Früherkennung von Störungen.
Listing 1: Beispieldaten mit Pilzbestandteilen
+---------+---------+---------+-------+---------+----------+-----------+-----------+ | class|cap-shape|cap-color|bruises|veil-type|gill-color|ring-number|spore-color| +---------+---------+---------+-------+---------+----------+-----------+-----------+ | edible| convex| yellow|bruises| partial| white| 1| black| | edible| flat| brown| null| partial| gray| 1| black| |poisonous| convex| brown|bruises| partial| pink| 1| brown| |poisonous| convex| yellow| null| partial| pink| 1| null| |poisonous| flat| gray|bruises| partial| chocolate| 1| chocolate| | edible| knobbed| red|bruises| partial| white| 2| white| |poisonous| flat| red| null| partial| white| 0| white| +---------+---------+---------+-------+----------+---------+-----------+-----------+
Wenn im Herbst die Pilzsaison startet, stellt sich für jeden Pilzsammler die Frage, ob ein Pilz essbar oder giftig ist. In vielen Städten und Landkreisen gibt es daher das Angebot, sich von einem Fachmann beraten zu lassen. Dieser Artikel beleuchtet die Konzepte von Spark ML anhand eines Anwendungsszenarios aus diesem Bereich. Entstehen soll ein Modell für die maschinelle Pilzberatung, das Ergebnis ist allerdings ohne Gewähr. Ausgangsbasis ist das Mushroom Classification Dataset, das die University of California in Irvine dem Unternehmen Kaggle zur Verfügung gestellt hat. Das Datenset enthält 8416 Datensätze zu verschiedenen Pilzen. Für unser Beispiel haben wir die Originaldaten angepasst und die Anzahl der Attribute reduziert (Listing 1).
Die Spalte class mit den Werten edible (essbar) und poisonous (giftig) soll das Modell in Abhängigkeit einer Auswahl von den anderen Attributen vorherzusagen lernen. Es handelt sich dabei um Eigenschaften der Morphologie eines Pilzes wie Farbe der Pilzkappe, der Lamellen und des Stiels sowie Anzahl der Ringe. Insgesamt enthält das vereinfachte Datenset 7 solcher Eigenschaften (Features). Das vorherzusagende Attribut class wird als Label bezeichnet.
Unser Modell für die maschinelle Pilzberatung soll auf der Random Forest Classification aufbauen, einem Klassifikationsverfahren, das auf einem Ensemble von Entscheidungsbäumen (Decision Tree) beruht. Die Tatsache, dass mehrere Entscheidungsbäume für die Klassifikation herangezogen werden, gibt dem Verfahren seinen Namen. Die Random Forest Classification ist ein Vertreter aus dem Bereich des Supervised Learning, das heißt, man benötigt für das Training ein vorklassifiziertes Datenset. Das Mushroom Dataset erfüllt diese Voraussetzung, da es bereits eine Einstufung in „essbar“ und „giftig“ für jeden Eintrag enthält. Auf Basis der Trainingsdaten entsteht ein Klassifikationsmodell, bestehend aus einer definierten Anzahl verschiedener Entscheidungsbäume, die gleichberechtigt und unabhängig voneinander zum Gesamtergebnis einer Klassifikation beitragen. Es handelt sich demnach um ein Voting-Verfahren, wo das Mehrheitsergebnis das Gesamtergebnis der Klassifikation darstellt. Ziel ist es, auf der Grundlage des so erlernten Modells neue, bisher noch unbekannte Daten aus der gleichen Domäne zu klassifizieren.
Listing 1 stellt einen Ausschnitt der Mushroom-Daten dar. Enthalten sind neben der Klassifikation in „essbar“ und „giftig“ unter anderem die Farben verschiedener Pilzbestandteile. Die Attribute bruises (Quetschung) und spore-color (Sporenfarbe) weisen Nullwerte auf.
Datenaufbereitung und Analyse
Zunächst gilt es, sich einen Überblick über die Daten zu verschaffen. Wie viele Werte gibt es pro Feature? Wie sind die Wertebereiche? Gibt es Nullwerte? Liegen die Daten erst einmal als DataFrame vor, können derartige Aufgaben mit Spark SQL oder der DataFrame-API erledigt werden. In unserem Fall bietet sich an, die Daten des Mushroom Dataset mithilfe der read-Funktion der Spark Session in den DataFrame df einzulesen. Da noch mehrfach darauf zugegriffen werden wird, weist man Spark mit cache() an, die Daten nach dem ersten Zugriff im Hauptspeicher zu halten.
Listing 2: ReadDescribe
var df = spark.read
.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("<path>/mushrooms_ix.csv")
df.cache()
df.describe("class", "cap-shape", "bruises", "ring-number", "spore-color").show()
+-------+---------+---------+-------+---------+------------------+-----------+
|summary| class|cap-shape|bruises|veil-type| ring-number|spore-color|
+-------+---------+---------+-------+---------+------------------+-----------+
| count| 8416| 8416| 3376| 8416| 8416| 7989|
| mean| null| null| null| null|1.0655893536121672| null|
| stddev| null| null| null| null|0.2696347029978422| null|
| min| edible| bell|bruises| partial| 0| black|
| max|poisonous| sunken|bruises| partial| 2| yellow|
+-------+---------+---------+-------+---------+------------------+-----------+
Der Aufruf df.describe() (Listing 2) erzeugt einen DataFrame mit einfachen Statistiken, der mit show() angezeigt werden kann. Die Spaltenauswahl ist dabei optional. Zunächst wird ein DataFrame mit spark.read erzeugt. Mit describe können einfache Statistiken für einen DataFrame ausgegeben werden.