

Mit IT mehr Wissen schaffen
Ein langer Weg
Cognitive Computing stellt höchste Anforderung an die IT-Systeme. Auch wenn die Industrie bemüht ist, KI-Systeme voranzutreiben, gibt es noch viel zu tun, bis künstliche Systeme wirklich „intelligent“ sind.
In Berlin startete kürzlich ein Projekt der Polizei zur automatischen Gesichtserkennung. Darin lernt ein IT-System, Gesichter von Passanten den vorhandenen Datensätzen von 250 Kandidaten zuzuordnen. Die Gesichtserkennung ist insofern ein typisches Beispiel für Cognitive Computing, als sie Wissen erwirbt und zu bestimmten Zwecken bereitstellt.
Das Polizeiprojekt soll nicht weniger als ein halbes Jahr dauern. Diesen Zeitraum benötigt der Computer, um unter Einsatz von Deep Learning (DL) das Modell, mit dem er Gesichter bewertet, zu trainieren. Dabei muss er Millionen von Bildern, sogenannte Events, erfassen und auswerten.
Durch Tagging der Bilder und Gewichtung von Parametern könnte der Programmierer des Algorithmus dem Rechner immer wieder mitteilen: „Dies ist Kandidat A, dies Kandidat B, aber der hier ist unbekannt.“ Das System „lernt“ mit dem Algorithmus, die Kandidaten zu erkennen und voneinander zu unterscheiden. Dafür muss es seinen Algorithmus immer wieder durch Korrekturen anpassen, bis sich die Confidence, also Treffsicherheit, der Marke von 100 Prozent nähert, diese aber niemals erreichen dürfte.
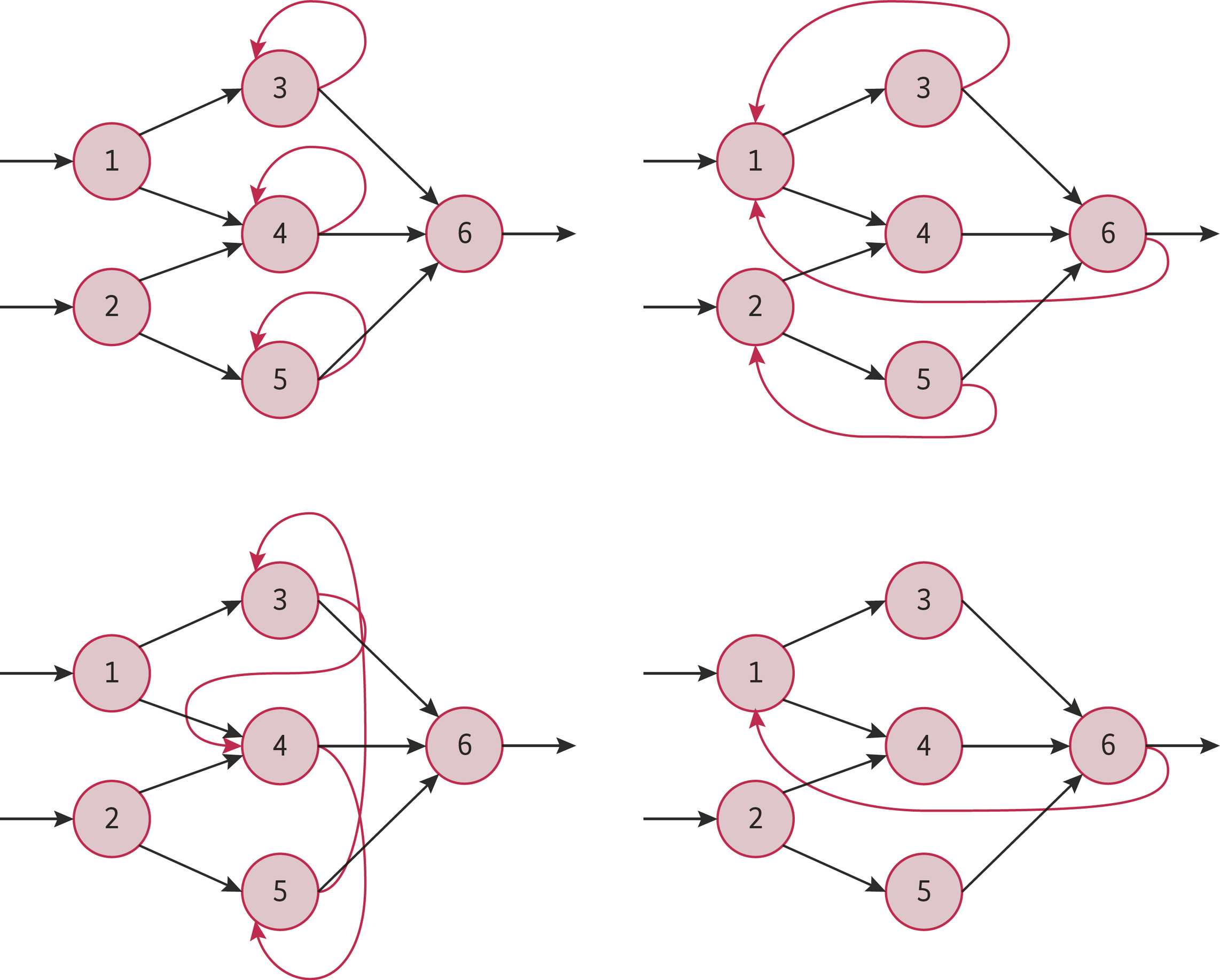
Dazu wird das Modell für die Gesichtserkennung in seine Bestandteile zerlegt und durch einen geeigneten Typ eines neuronalen Netzes geschickt. Als Beispiel soll ein rekurrentes neuronales Netz (RNN) dienen. Die Knoten der vielen Ebenen und parallelen Ausführungsstränge liefern ihre Ergebnisse an die jeweils nächsten Ebenen, zuweilen aber auch an sich selbst oder an Knoten derselben oder dahinterliegender Ebenen, die damit wiederum neue Berechnungen vornehmen (siehe Abbildung 1). Schon bald lässt sich beobachten, dass die Bilder schärfer werden und viele Passanten unbeachtet bleiben, das System aber die Kandidaten herauspickt.
Im RNN laufen immer die beiden Phasen des Trainierens und Anpassens sowie der Schritt der Inferenz ab, also die Anwendung der Hypothese auf die Realdaten. Training, Inferenz und Anpassung des Modells sind die Schritte, die Deep Learning mit neuronalen Netzen so aufwendig machen. Allein schon das Training erfordert die Auswertung großer Datenmengen, beispielsweise 100 Millionen getaggte Bilder. Hinzu kommen die ständige Inferenz zwischen den Schichten und die Verarbeitung des Resultats. 120 TByte in einem In-Memory-Cluster zu halten, ist inzwischen eine normale Aufgabe. Die Parallelisierung dieser Arbeitsschritte ist der einzige Weg, um Deep Learning effizient zu bewältigen.
Statistik als Grundlage
Dagegen bezeichnet Machine Learning (ML) die Obermenge, die Deep Learning enthält. Dies ist das Reich der Algorithmen und ihrer Implementierung für die unterschiedlichsten Einsatzszenarien. Da sich Modelle auch in klassischen Statistikpaketen sowie in der Statistiksprache R entwickeln und verwenden lassen, ist der Anwender keineswegs auf die Methoden des mehrschichtig arbeitenden Deep Learning angewiesen. Die meisten Algorithmen existieren seit den 1950er-Jahren und genießen große Verbreitung. Recommendation Engines auf E-Commerce-Sites oder Googles Suchmaschine verwenden sie schon lange.
Für Aufgaben, die über Deep und Machine Learning hinausgehen, haben sich die Schlagwörter künstliche Intelligenz (KI) oder Artificial Intelligence (AI), Data Science oder Cognitive Computing verbreitet. Für Prof. Michael Resch vom Höchstleistungsrechenzentrum Stuttgart (HLRS) ist Intelligenz ein kulturhistorischer Begriff, der nicht auf IT-Systeme angewandt werden sollte. Auch „künstliche Intelligenz“ ist ein schwammiger Begriff, der seit den Fünfzigerjahren umgeht und mittlerweile nicht mehr die banale Nachbildung der menschlichen Intelligenz meint, sondern vielmehr deren Erweiterung.
Auch das Max-Planck-Institut für Intelligente Systeme (MPI-IS) und das Deutsche Forschungszentrum für Künstliche Intelligenz (DFKI), an dem auch Google beteiligt ist, fassen den Begriff KI so auf. Beide haben zahlreiche Projekte verwirklicht, die dem Menschen dienen und sein Wissen erweitern sollen. Robotik ist das bekannteste Einsatzgebiet für „intelligente“ mobile Systeme, ein anderes sind cyber-physische Systeme. Darunter versteht man Systeme mit eingebetteter Software und Elektronik, die über Sensoren und Aktoren mit der Außenwelt interagieren.
Mit 800 Mitarbeitern ist das DFKI das weltweit größte Zentrum für KI-Forschung. Die Forscher, die mit der Industrie zusammenarbeiten, entwickeln „intelligente“ Kleidung, „intelligente“ medizinische Geräte, AR- und VR-Systeme, sprecherunabhängige maschinelle Übersetzung, „intelligente“ M2M-Schnittstellen, Wirtschaftsinformatik, Big Data Analytics und vieles mehr.
Bei DFKI & Co. taucht immer wieder der Begriff „Companion“ auf: Das KI-System ist dem Nutzer ein lernfähiger und unterstützender Assistent und Begleiter, der in der Lage ist, Sprache, Gesichtsausdruck, Gestik und vieles mehr zu verstehen und passend zu reagieren. Das Modul zur Datenverarbeitung kann im Gerät selbst untergebracht sein oder in einem angebundenen Cluster.