

Deepfakes: KI gegen KI
Deepfakes, also gefälschte Bilder und Videos, entstehen mit gegeneinander arbeitenden KIs. Neue Methoden – ebenfalls mit KI – entlarven die Fälschungen.

(Bild: Fractal Pictures/Shutterstock.com)
- Christian Schwerdt
Die viralen Bilder von Papst Franziskus in weißer Daunenjacke und von Donald Trump bei seiner Verhaftung sowie das Video von Franziska Giffey in ihrer Unterhaltung mit Vitali Klitschko haben eines gemeinsam: Sie sind gefälscht – mit KI, sogenannte Deepfakes. Deepfakes sind Fluch und Segen zugleich: Ein kreatives Werkzeug für Künstlerinnen und Künstler einerseits, können Kriminelle sie andererseits für Fake-News-Kampagnen oder Phishing-Attacken missbrauchen.
Die jüngsten Fortschritte im Bereich der Künstlichen Intelligenz haben einen steilen Aufstieg in der Entwicklung von Deepfake-Techniken ausgelöst: von KI manipulierte Inhalte, die eine verblüffende Realitätsnähe erreichen. Als synthetische Ausgabemedien umfassen sie Videos, Audio, Bilder und Texte.
Wenn Videos lügen
Zwei Fortschritte haben diese Revolution in der Bildverarbeitung ermöglicht: Einerseits haben Forscherinnen und Forscher Algorithmen entwickelt, die Gesichtsmerkmale in Bildern erkennen und replizieren, wie die Position von Augenbrauen, Nase, Mund und Ohren. Andererseits sind Plattformen für Videos und Fotos weitverbreitet und liefern umfangreiche audiovisuelle Daten, die eine KI analysieren und manipulieren kann.
Bekannte Anwendungen, um Deepfakes herzustellen, sind die Tools DeepFaceLab oder Lensa AI, die Personen in Videos, Audiodateien und Live-Streams (Videotelefonaten) auswechseln. Die Deepfake-Erzeuger montieren das Gesicht einer anderen in die ursprüngliche Person im Video hinein. Die Tools schaffen es dabei dank KI, dass Mimik und Stimme täuschend echt wirken.
Deepfake-Werkzeuge nutzen dabei zwei KI-Methoden: Generative Adversarial Networks (GANs) und Autoencoder. GANs sind maschinelle Lernverfahren, die eine große Anzahl von Bildern durchsuchen und daraus neue, qualitativ vergleichbare generieren. Ein GAN besteht aus zwei Teilen: dem Generator und dem Diskriminator (siehe Abbildung 1), wobei beides neuronale Netzwerke sind. Der Generator versucht, authentisch wirkende Daten zu kreieren, während der Diskriminator die Aufgabe hat, diese Daten als künstlich zu erkennen und von echten zu unterscheiden. Dieses Urteil gibt er dem Generator als Feedback zurück.
Zu Beginn des Trainings produziert der Generator häufig offensichtliche Fälschungen, die der Diskriminator leicht aufdeckt. Mit fortschreitendem Training erschafft der Generator jedoch zunehmend realistischere Darstellungen, was die Trefferquote des Diskriminators verringert.

(Bild: Christian Schwerdt)
Zum Fälschen arbeitet das GAN mit zwei Videos als Eingabe: Das erste enthält eine Person, die durch eine andere Person aus Video 2 ersetzt werden soll. Mit fortschreitendem Training verbessert das GAN seine Entwürfe, bis sie am Schluss schwer als Fälschung aufzudecken sind.
Im Gegensatz zum GAN extrahieren Autoencoder Gesichtszüge aus Bildern, um neue Bilder zu kreieren, die im Vergleich zum Original unterschiedliche Ausdrücke oder Bewegungen aufweisen (siehe Abbildung 2). Autoencoder gehen methodisch in zwei Phasen vor: Zunächst erfasst ein neuronales Netz als Encoder relevante Charakteristika der Gesichtszüge aus dem Quellbild und wandelt diese in Merkmalsvektoren um. Diese Vektoren verarbeitet es sequenziell durch verschiedene Netzschichten und integriert sie in ein kohärentes Modell. In der zweiten Phase dekodiert eine KI die Vektoren, wobei das Gesicht entsprechend den Manipulationsvorgaben neu ausgerichtet und nahtlos in das Originalbildmaterial eingefügt wird. Um ein Deepfake effektiv durch einen Autoencoder zu erstellen, bedarf es einer umfangreichen Sammlung an Bild- oder Videomaterial des Zielgesichts.
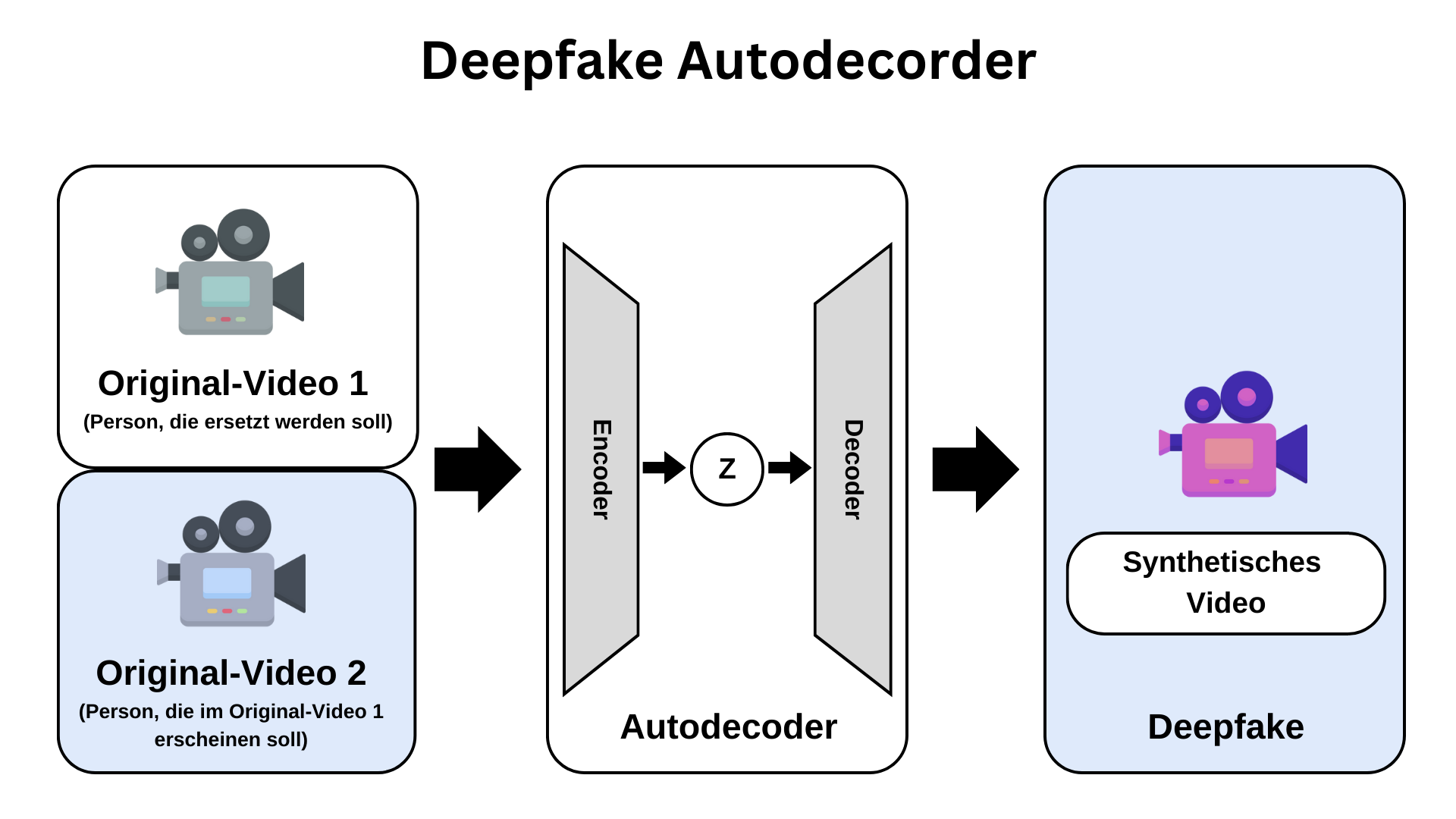
(Bild: Christian Schwerdt)
GANs benötigen im Vergleich zu Autoencodern einen erheblich höheren zeitlichen Aufwand und ein iteratives Vorgehen. Sie verbrauchen eine große Menge an Grafikprozessor-Rechenleistung. Aktuell werden GANs vornehmlich zur Erstellung realistischer Bilder genutzt.
Gefahren gefälschter Audiodokumente
Neben dem Gesicht zählt die Stimme zu den zentralen Ansatzpunkten einer Personenfälschung. Für eine gelungene Stimmimitation spielt nicht nur der authentische Klang eine Rolle, sondern auch ein überzeugender Inhalt der Audioaufnahme. Der Klon sollte im Stil und Vokabular der imitierten Person echt klingen. Eine gesteigerte Gefahr hinsichtlich Audio-Deepfakes besteht darin, dass die Erzeugung ausgesprochen einfach ist: Als Ausgangsmaterial genügen bereits fünfzehn Minuten Sprachaufnahmen des Opfers.
Hierfür kommen zwei essenzielle Techniken zum Einsatz: das Text-zu-Sprache- und das Imitationsverfahren. Bekannte Tools im Bereich Text-zu-Sprache-Verfahren (Text-to-Speech, siehe Abbildung 3) sind Lovo AI, Synthesys und Murf. Sie übertragen beliebigen Text unter Berücksichtigung der sprachlichen Eigenheiten der gewünschten Stimme nahtlos und in Echtzeit in natürlich klingende Sprache. Dieser Prozess besteht aus zwei Hauptstadien: Zunächst benötigen Fälscherinnen und Fälscher RAW-Audiodaten des Opfers und Transkripte. Auf deren Basis entsteht ein Generierungsmodell, das drei Kernelemente enthält: Textanalysemodul, akustisches Modul und Vocoder.
Das Analysemodul verarbeitet den Text und übersetzt ihn in sprachliche Eigenschaften. Das Akustikmodul bestimmt dann die spezifischen Parameter des Sprechers aus den Audiodaten, basierend auf den linguistischen Merkmalen des Textanalysemoduls. Abschließend generiert der Vocoder auf Grundlage dieser Parameter die stimmlichen Wellenformen und nimmt die finale Klangsynthese vor. Das Endprodukt ist ein synthetisch erzeugter Deepfake.

(Bild: Christian Schwerdt)
In den letzten Jahren hat sich der Einsatz von Text-zu-Sprache-Verfahren aufgrund ihrer Flexibilität und hohen Ergebnisqualität als besonders beliebt herausgestellt. Eine kürzlich durchgeführte britische Studie belegt, dass Nutzer Schwierigkeiten haben, echte Stimmen von Stimmklonen zu unterscheiden. Überraschenderweise half selbst ein gezieltes Training der Studienteilnehmer nicht, diese Audio-Deepfakes zu entlarven.
Wie gut Audio-Fakes sind, hängt von der Qualität der RAW-Daten ab. Diese aufzubauen, ist häufig kosten- und zeitintensiv. Zudem haben viele Sprachsynthesesysteme Schwierigkeiten, Satz- und spezielle Zeichen zu erkennen. Ambiguitäten, bei denen gleich geschriebene Satzstrukturen und Wörter verschiedene Bedeutungen haben, bleiben ebenfalls eine Herausforderung.
Das zweite, das Imitationsverfahren, arbeitet mit nur wenigen RAW-Daten und hat das Ziel, die ursprüngliche Sprachaufnahme eines Sprechers so zu verändern, dass sie klingt, als hätte sie ein anderer Sprecher − das Ziel – gesprochen (siehe Abbildung 4). Dabei nimmt ein Algorithmus ein gesprochenes Signal auf und modifiziert es, indem er dessen Stil, Intonation oder Rhythmus ändert, ohne die linguistischen Informationen zu verändern. Diese Technik wird auch als sogenannte Stimmumwandlung bezeichnet.

(Bild: Christian Schwerdt)
Diese Methode wird häufig mit der zuvor genannten verwechselt, denn beide modifizieren rhythmische und stilistische Merkmale des Sprachaudiosignals. Der Unterschied besteht darin, dass die imitationsbasierte Methode den Eingabe- und Ausgabetext unverändert lässt. Sie passt nur die Art und Weise an, wie der Satz gesprochen wird, um die Charakteristik des Zielsprechers zu treffen.
Eine weitere Deepfake-Technik ist die geschriebene und nicht gesprochene Textsynthese, die Texte im individuellen Schreibstil einer bestimmten Person generiert. Natural Language Processing analysiert große Textmengen und transkribiert Audioaufnahmen. Die Fälscherinnen und Fälscher schaffen damit täuschend echt wirkende Aussagen, die auf Plattformen wie X oder Facebook als Fake-News landen.
