

Data Mining für Salesforce-Daten mit Azure ML
Schätze finden
Wenn es um die Auswertung großer, komplexer Datenmengen geht, sind Spezialwerkzeuge gefragt. Etwa Microsofts Cloud-Tool Azure Machine Learning.
Der letzte Artikel der Salesforce-Serie [5] zeigte Möglichkeiten des Datenaustauschs zwischen der Salesforce-Cloud und Microsoft Azure exemplarisch für einen beliebigen Cloud-Service von Drittanbietern. Dieser Artikel geht einen Schritt weiter und beschreibt, wie man Salesforce-Daten in der Azure-Cloud mithilfe von Azure Machine Learning (Azure ML) analysiert.
Azure ML ist ein Cloud-Dienst für die Auswertung großer Datenmengen mithilfe von Data-Mining-Algorithmen. Die Implementierung als Cloud-Service hat den Vorteil, dass die Verarbeitung nahezu beliebig parallelisierbar beziehungsweise skalierbar ist, ohne dass man entsprechende eigene Rechnerkapazitäten aufbauen müsste. Die dabei entstehenden Modelle können sogar mithilfe von Webservices anderen Anwendungen bereitgestellt werden. Auch eine Excel-Integration steht zur Verfügung.
Für kleinere Data-Mining-Experimente gibt es Azure ML kostenlos. Dabei sind jedoch die Komplexität der Daten, der Speicherplatz und der Grad der Parallelisierung eingeschränkt.
CRM durch maschinelles Lernen aufwerten
Zum Einstieg bietet Microsoft das Azure Machine Learning Studio (siehe „Alle Links“ am Ende des Artikels) an, eine Webanwendung, die das Erstellen von Projekten und deren Artefakte (Experimente, Webservices, Notebooks, Data Sets und trainierte Module) organisiert.
Dreh- und Angelpunkt der Oberfläche sind die Experimente, mit denen der Anwender Daten analysieren und Modelle trainieren kann. Auf der Basis der Experimente werden diese trainierten Modelle als Webservice anderen Anwendungen zur Verfügung gestellt. Im Detail funktioniert das so:
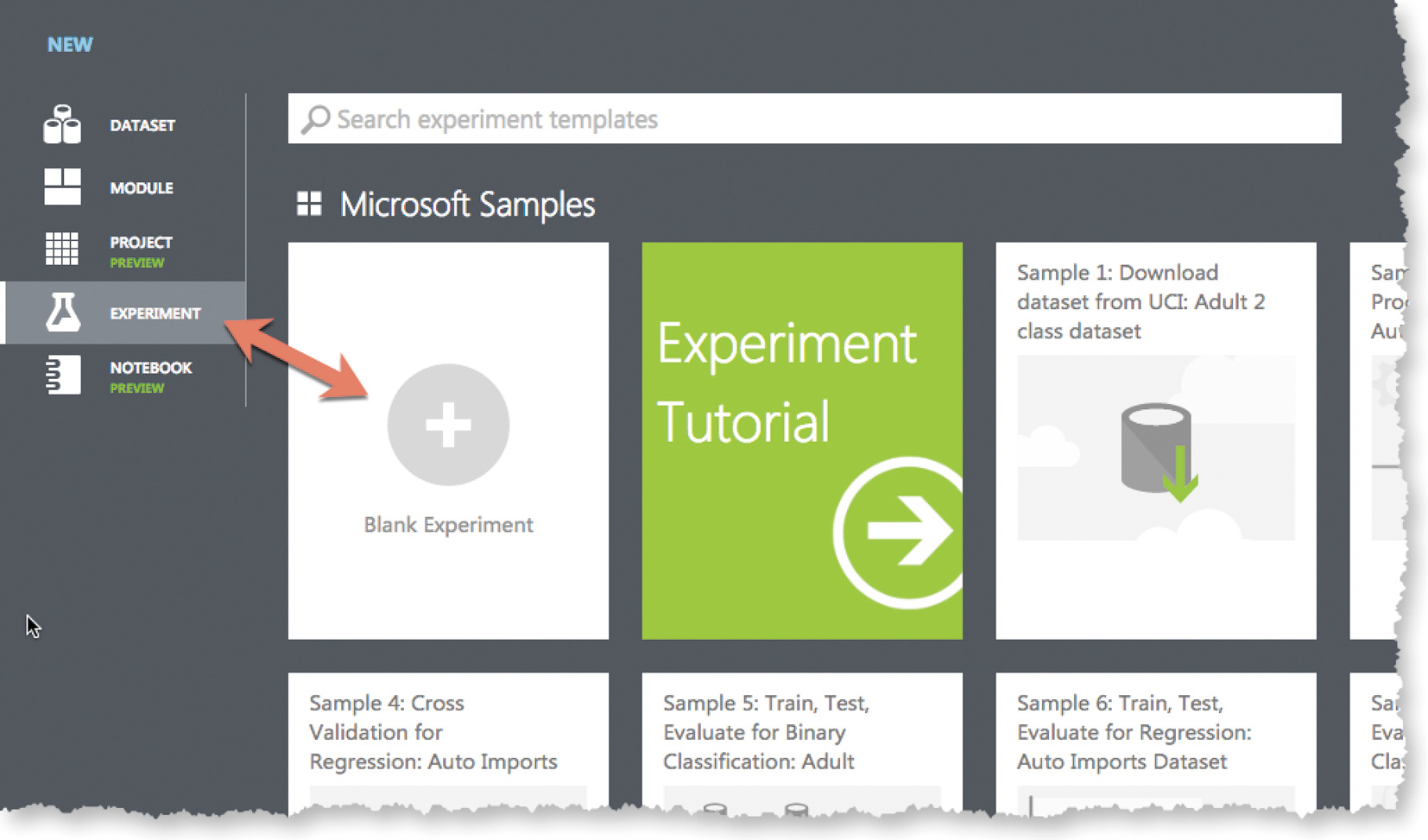
Ist ein neues Experiment mithilfe des „New“-Schalters unten links im Studio erstellt, kann man in der Galerie ein leeres Experiment unter dem Menüpunkt „Experiment“ auf der linken Seite auswählen.
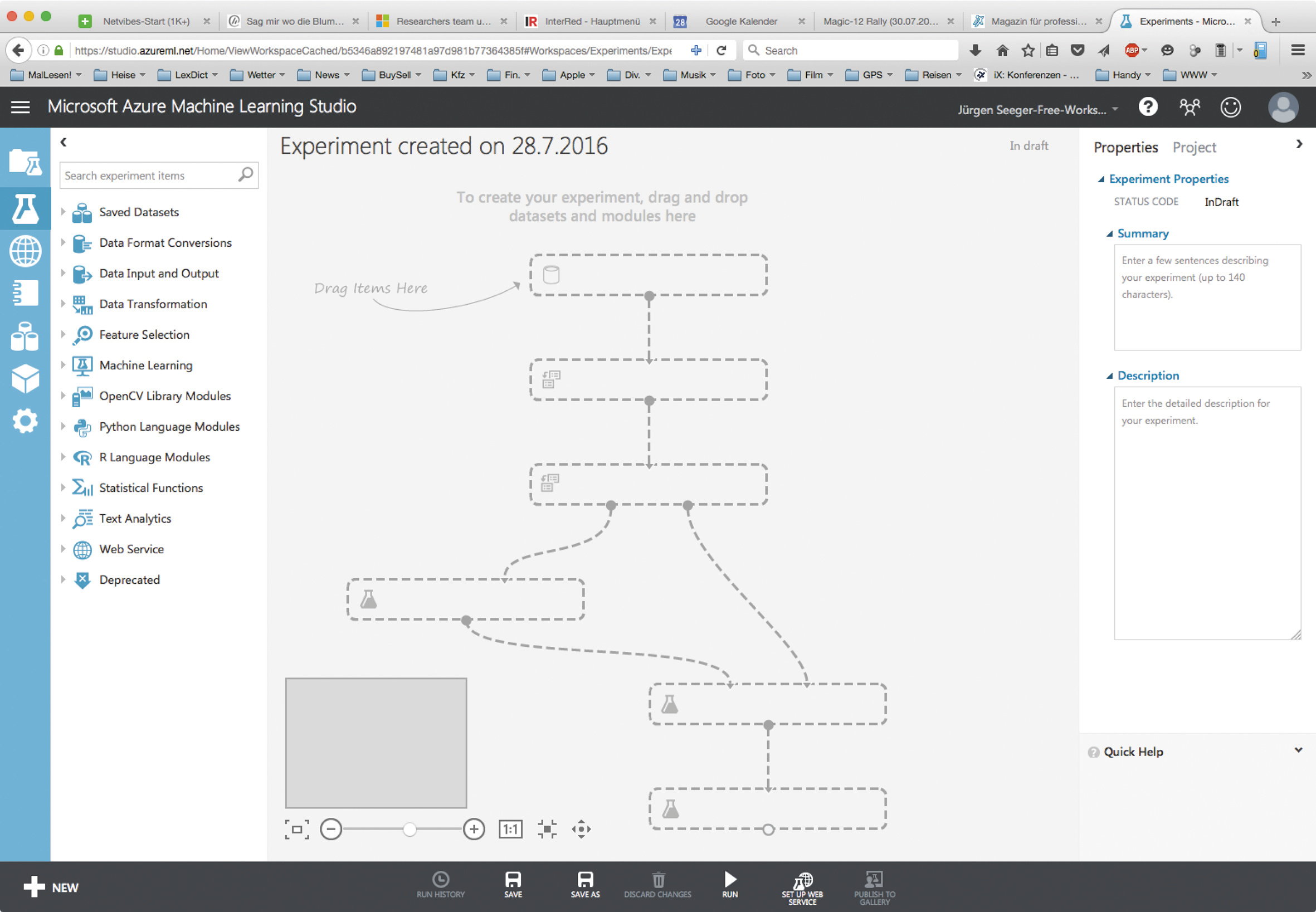
Dadurch wird die Entwicklungsoberfläche für das leere Experiment geöffnet. Mithilfe dieser Oberfläche lassen sich die einzelnen Module des Experiments sowie deren sequenzieller oder paralleler Ablauf konfigurieren.
Ähnlich wie der Schemagenerator in Salesforce (der zur Konfiguration der Salesforce-Datenbank im Artikel „Nach Maß“ [2] verwendet wurde) besteht diese Oberfläche aus einer zentralen Arbeitsfläche zur Konfiguration des Experiments. Die zur Verfügung stehenden Module befinden sich auf der linken Seite. Die rechte Seite bietet Zugriff auf die Eigenschaften des Experiments sowie der verwendeten Module. Im unteren Bereich sieht man Schaltflächen zum Speichern und Ausführen des Experiments sowie für das Erstellen eines darauf basierenden Webservice (dazu später mehr).
Im Rahmen dieses Artikels sollen die Coupons ausgewertet werden, die in den bisher veröffentlichten Artikeln dieser Serie in die Salesforce-CRM-Umgebung geladen wurden. Diese Daten enthielten unter anderem die Information, welche Coupons ein Haushalt in der Vergangenheit eingelöst hat. Dies soll zum Anlernen eines sogenannten Apriori-Modells dienen, das dann für einen Haushalt Vorschläge für weitere Coupons unterbreiten kann.
Ein typisches Data-Mining-Experiment
Solche Apriori-Modelle sind typischerweise für Warenkorbanalysen im Handel im Einsatz, um dem Kunden ähnliche Produkte vorzuschlagen („Kunden, die dieses Produkt gekauft haben, haben auch folgende Produkte gekauft“). Aufgrund der Ähnlichkeit zum hier beschriebenen Anwendungsfall passt dieser Algorithmus.
In einem typischen Data-Mining-Experiment lernt man ein Modell zunächst mit sogenannten Trainingsdaten an und prüft es anschließend mit Testdaten. Dazu teilt man die vorhandenen Daten auf, beispielsweise in 80 % für Training, 20 % für Tests. Beim Apriori-Modell verhält sich dies etwas anders, da es sich um eine Mustererkennung auf Basis aller vorhandenen Daten handelt. Diese werden für das Training verwendet, um für die einzelnen Haushalte den nächsten Coupon aus den gelernten Regeln abzufragen.
Das regelmäßige Abfragen erfolgt dann durch ein weiteres Azure-ML-Experiment, da dafür das Modell nicht jedes Mal neu trainiert werden muss. Stattdessen wird das fertige Modell abgelegt und wiederverwendet.
Konfiguration des Experimentaufbaus
Das erste Experiment zum Trainieren des Modells kann man in Azure ML Studio per Drag-and-Drop konfigurieren. Doch zunächst müssen die Trainingsdaten vom Salesforce CRM als CSV-Download bereitgestellt und über das „Import Data“-Modul in das Azure-ML-Experiment importiert werden. Das funktioniert, wie im Artikel „Wolke an Wolke“ [5] beschrieben, über einen Webzugriff.
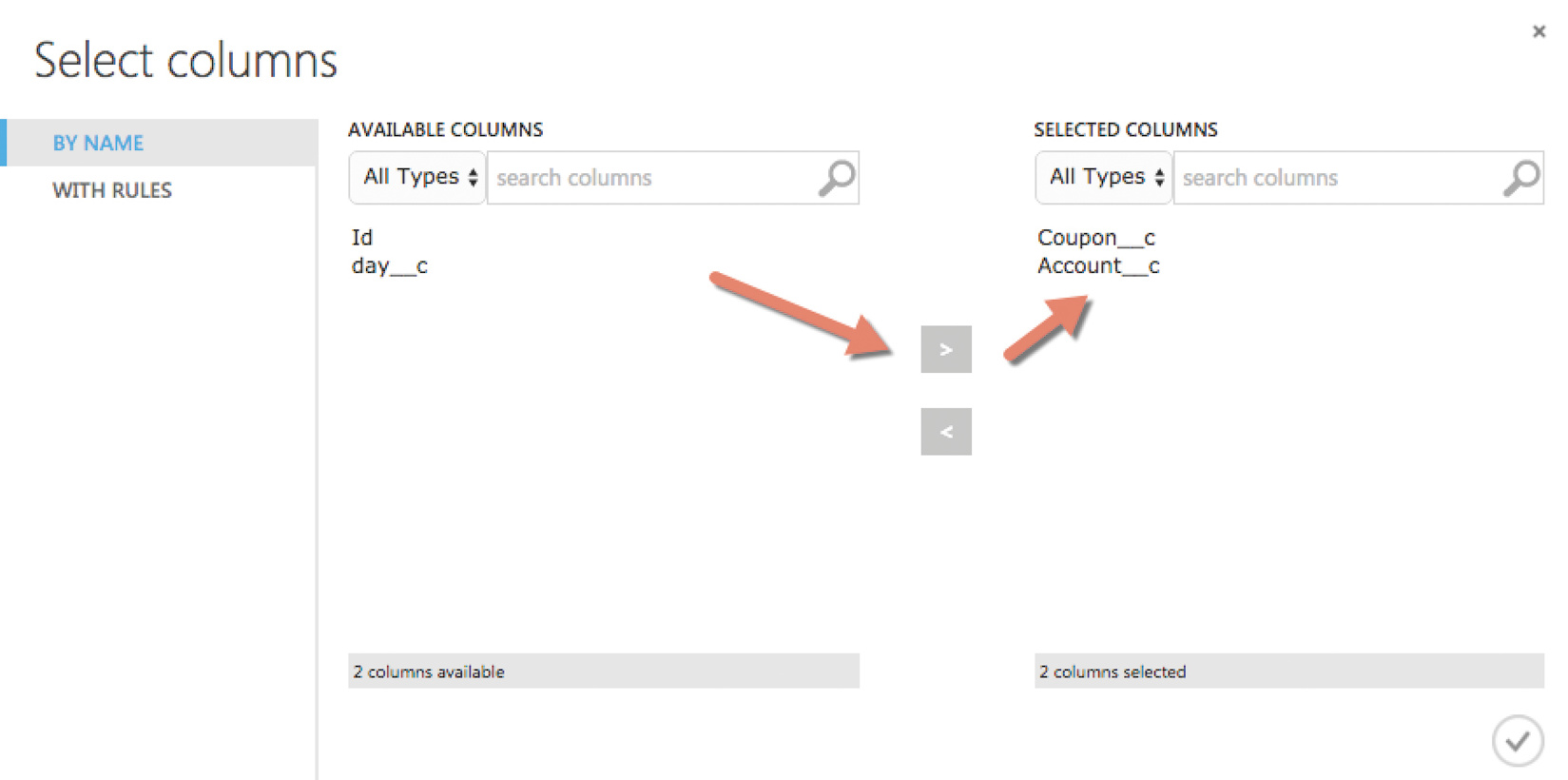
Um das Experiment zu beschleunigen, sollte man die tatsächlich benötigten Attribute verwenden, nämlich Account__c und Coupon__c. Das erledigt das Modul „Select Columns in Dataset“.
Damit stehen die Daten für das Experiment zur Verfügung. Als Nächstes wird ein Data-Mining-Modell benötigt. Leider fehlt bei Azure MLs von Haus aus mitgelieferten Data-Mining-Modellen ausgerechnet die Warenkorbanalyse mittels Apriori. Doch man kann eigene Module bauen, in R oder Python.
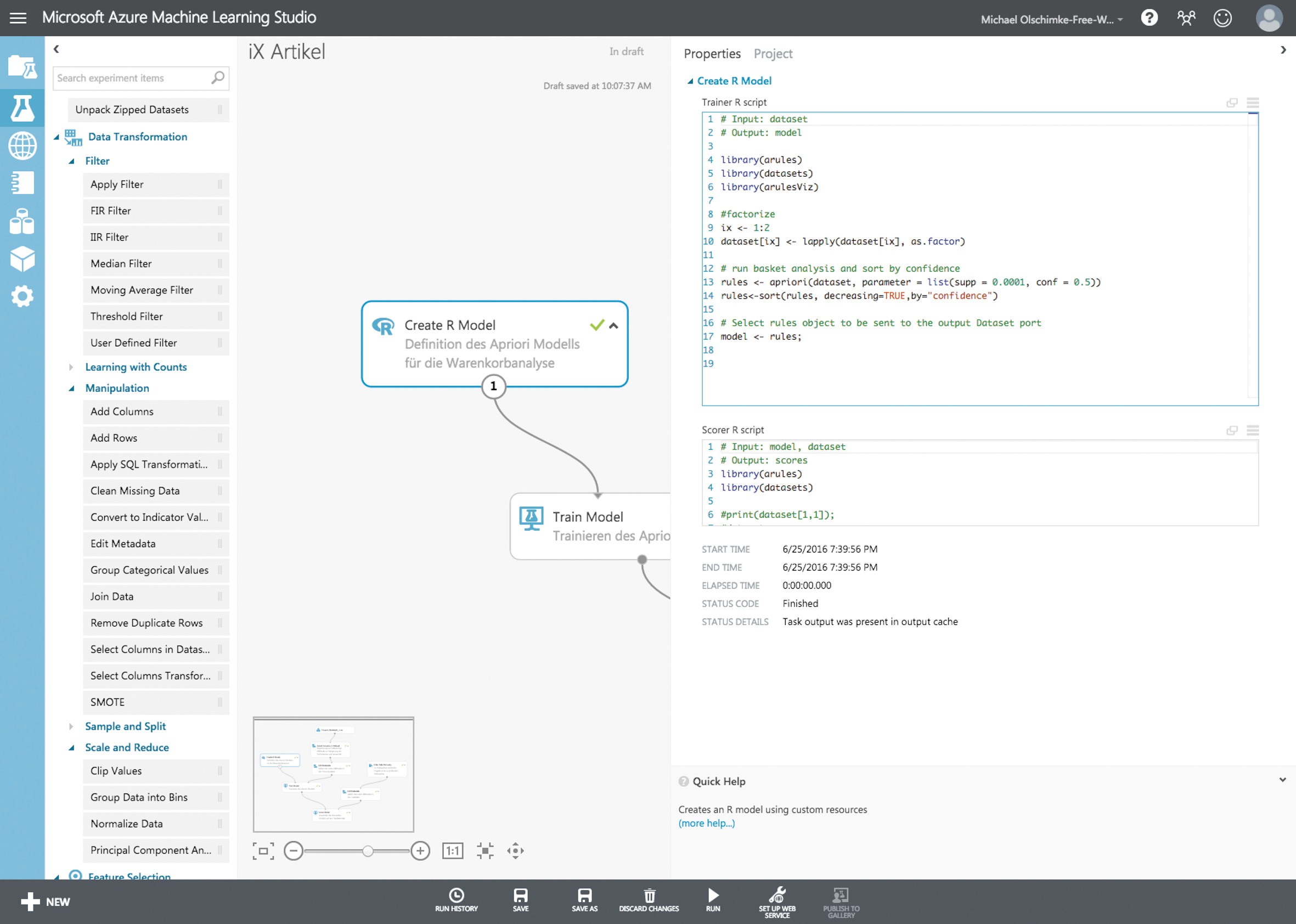
Über das Modul „Create R Model“ lässt sich ein Modell in der für statistische Zwecke entwickelten Sprache R erstellen, das man dem Experiment hinzufügt, jedoch zunächst nicht mit den bestehenden Modulen verbindet. Stattdessen wird der Quellcode für das Modell in R eingegeben.
Listing 1: R-Skript zum Trainieren des Data-Mining-Modells
# Input: dataset
# Output: model
library(arules)
library(datasets)
#factorize
ix <- 1:2
dataset[ix] <- lapply(dataset[ix], as.factor)
#pivot the data set
#dataset <- dataset[c("Account__c", "Coupon__c")] # order columns
dataset <- unique(dataset);
dataset <- as(split(dataset[,"Coupon__c"], dataset[,"Account__c"]), "transactions")
# run basket analysis and sort by confidence
rules <- apriori(dataset, parameter = list(supp = 0.01, conf = 0.5))
rules<-sort(rules, decreasing=TRUE,by="confidence")
# Select rules object to be sent to the output Dataset port
model <- rules;
Das erste Skript dient dem Erstellen und Trainieren des Modells und ist in Listing 1 dargestellt.
Flexibles Erweitern mit R oder Python
Zur Laufzeit bekommt das Skript eine Variable dataset zur Verfügung gestellt, die die Trainingsdaten repräsentiert. Das erstellte Modell wird über die Variable model zurückgegeben.
Im ersten Schritt werden die R-Pakete arules (für den Apriori-Algorithmus) und datasets (für die Verarbeitung der Datenmengen) importiert. Danach sind die Attribute im importierten Trainingsdatensatz zu faktorieren. Weiterhin gilt es, das Dataset in ein Format zu bringen, das den Erwartungen des Apriori-Algorithmus entspricht: eine „pivotisierte“ Ansicht, in der für jeden von einem Haushalt (Account) eingelösten Coupon eine Spalte existiert.
Nun kann die Mustererkennung mit dem Apriori-Algorithmus starten. Der ist in diesem Fall zu Demonstrationszwecken so konfiguriert, dass er möglichst viele Regeln erkennt (wenn auch schlechte). In der Realität sollte man dies stärker über die Parameter supp (für Support) und conf (für Confidence) einschränken.