

Apache-Projekte zur Analyse großer Datenmengen
Datenmassen kanalisieren
Unter dem Dach der Apache Software Foundation haben sich rund um Hadoop zahlreiche Open-Source-Projekte zur Erfassung, Verarbeitung, Speicherung und Auswertung von Big Data versammelt. Da stellt sich die Frage: Welche Software ist für welche Aufgaben am besten geeignet?
Letztes Mal beim Big-Data-Meetup: Vier ehemalige Kollegen unterhalten sich über Big-Data-Software.
Christopher: „Das ist ja lustig, jetzt haben wir uns so lange nicht gesehen und arbeiten doch alle mit Big-Data-Software der Apache Software Foundation!“
Julia: „Ist ja auch kein Wunder: Open Source, eine globale Entwickler-Community, Herstellerunabhängigkeit – was will man mehr?“
Jarek: „Erzählt mal – was macht ihr konkret?“
Christopher: „Ich nutze Apache Storm für die Sentiment Detection in Echtzeit. Die unstrukturierten Nachrichten werden als Textdateien im HDFS in Apache Hadoop abgelegt. Apache Calcite verwenden wir zur Echtzeit-Aggregation.“
Julia: „Echtzeit ist auch für mich ein heißes Thema. Ich verarbeite geolokalisierte Sensordaten von Fahrzeugen. Der Dateneingang erfolgt über Apache Kafka, anschließend fließen die Daten in Apache HBase. Apache Spark nutze ich zur Berechnung und die Abhängigkeit der Aggregate ist mit Apache Oozie modelliert.“
Jarek: „Ich konzentriere mich auf die Auswertung von Langzeitdaten, die im ORC-Format in Apache Hive gespeichert sind, mit Apache Zeppelin. Die Daten werden nur von Zeit zu Zeit per Batch-Job via Apache Sqoop aktualisiert.“
Große Softwarevielfalt
Das oben dargestellte Gespräch ist beispielhaft für den aktuellen Stand der Vielfalt an quelloffener Big-Data-Software, die sich praktisch komplett unter dem Dach der Apache Software Foundation (ASF) gesammelt hat. Denn obwohl alle drei letztlich mit dem Hadoop-Ökosystem der ASF arbeiten, setzen sie doch ganz unterschiedliche Techniken ein. Entwickler und Data Scientists stehen daher vor der Frage, wie sie angesichts der reichhaltig angebotenen Auswahl die am besten passende Big-Data-Technik für ihre Probleme finden – die Unterschiede zwischen den verschiedenen Projekten sind manchmal subtil.
Eine Zusammenstellung von Komponenten, die den eigenen Anwendungsfall optimal widerspiegelt, ist jedoch von zentraler Bedeutung. Sie sorgt nicht nur für eine erhebliche Arbeitserleichterung, sondern garantiert auch einen langfristig stabilen Betrieb des eigenen Big-Data-Stacks.
Funktionale Landkarte der Apache-Big-Data-Projekte
Bei der Suche nach der perfekten Lösung für die eigene Anwendung hilft es, die Top-Level-Projekte der Apache Software Foundation zunächst in ein funktionales Schema einzuordnen. Anschließend geht es um die Unterschiede zwischen auf den ersten Blick ähnlicher Technik für ähnliche Aufgaben. Die meisten Hadoop-Distributionen – die bekanntesten stammen von Hortonworks, Cloudera und MapR – enthalten sämtliche im Folgenden genannten Apache-Komponenten (die übrigens auch Grundlage der meisten Big-Data-Cloud-Angebote sind).
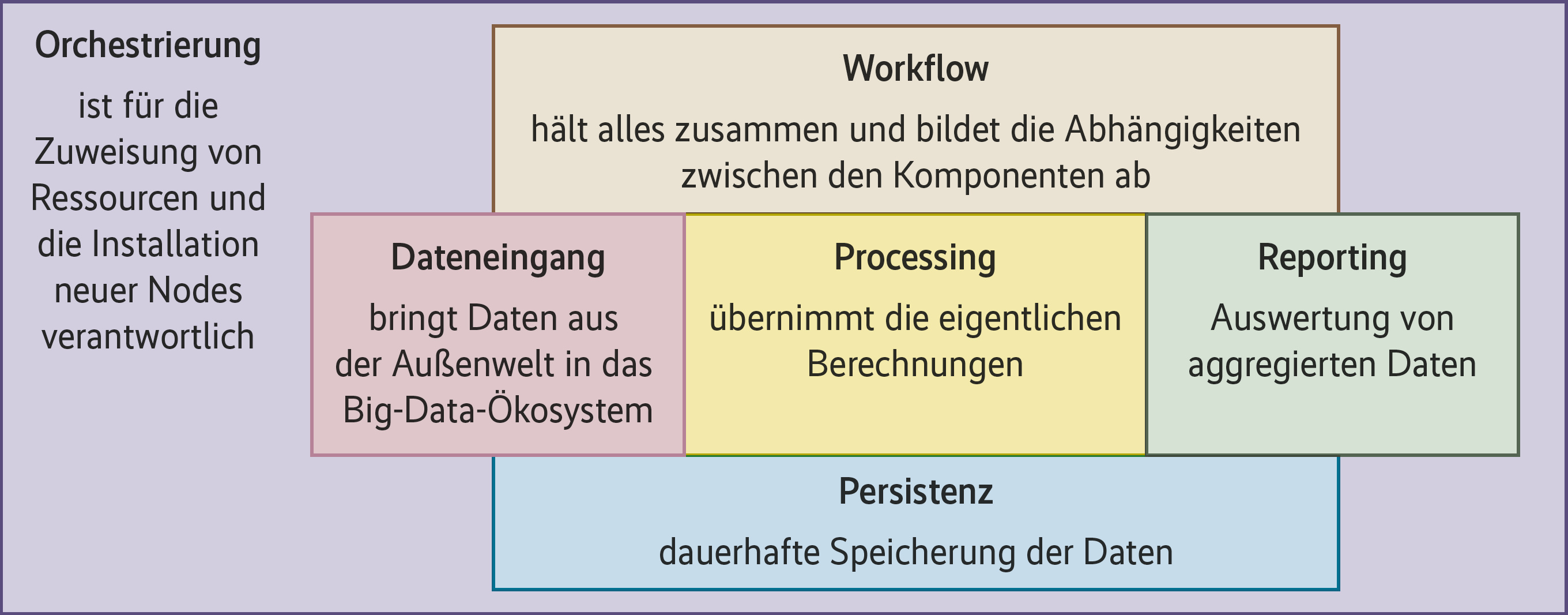
Der Versuch, die Big-Data-Software der ASF einzufangen, startet mit einer funktionalen Landkarte der Big-Data-Welt (Abbildung 1). Auf dieser Landkarte bildet Software zur Orchestrierung und Ressourcenverwaltung von Big-Data-Komponenten den Big-Data-Ozean. Die Big-Data-Kontinente nehmen die Projekte mit ihren unterschiedlichen Funktionen auf: Dateneingang, Workflow-Organisation, Datenauswertung, Persistenz, Reporting.
Auf den Kontinenten gibt es Länder mit Projekten, die ähnliche Funktionen in unterschiedlichen Ausprägungen für unterschiedliche Anwendungsfälle liefern. Um deren wichtigste Unterscheidungsmerkmale geht es im Folgenden.
Die hier vorgestellte Big-Data-Landkarte soll dazu beitragen, die verschiedenen Apache-Projekte einzuordnen und so den Einstieg zu erleichtern. Big Data bildet das Rückgrat der Industrie 4.0 – und viele Projekte werden mit Apache-Software implementiert.
Der Ozean: Orchestration und Allocation
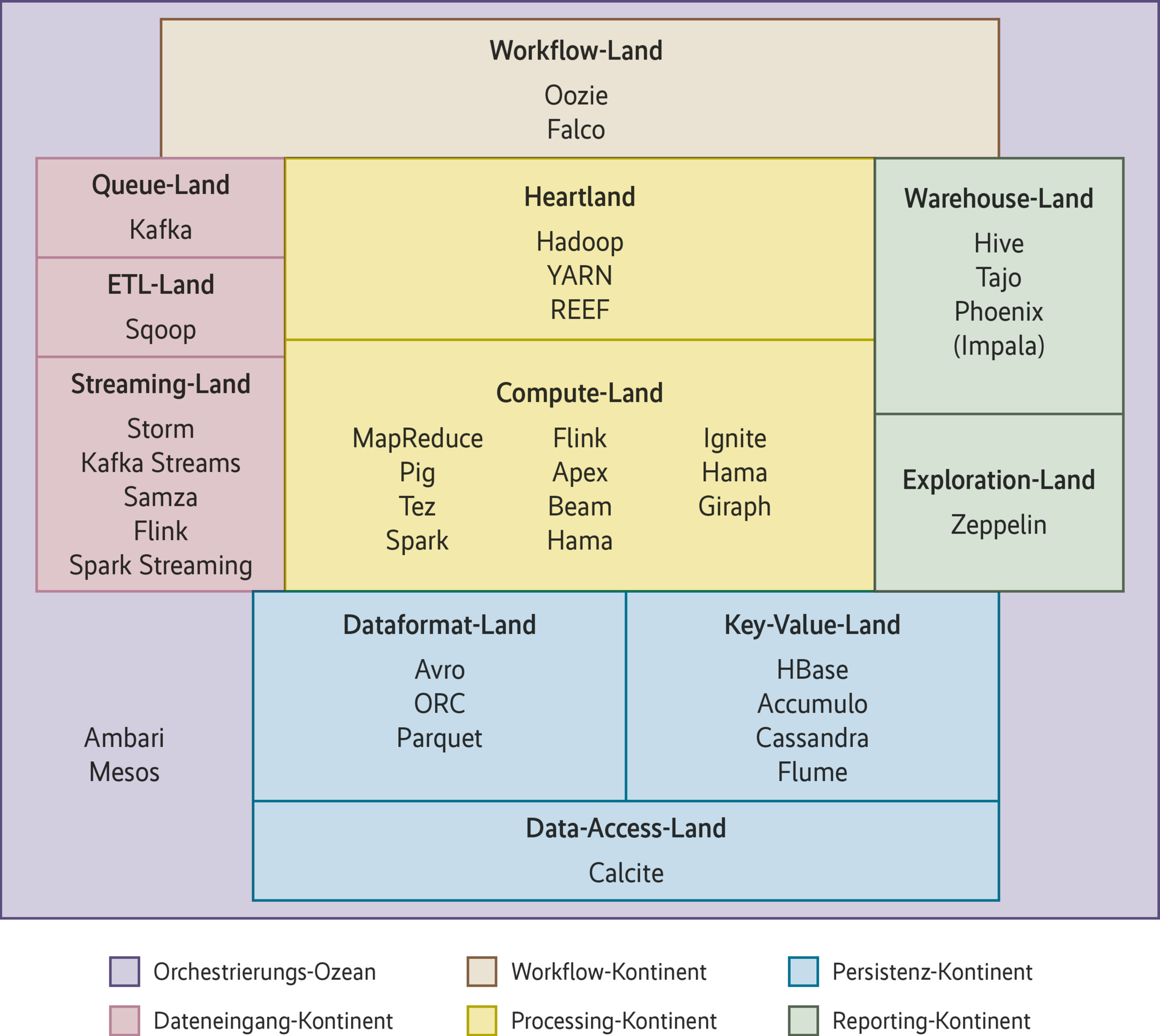
Apache Ambari hat sich als Standardwerkzeug zur Provisionierung von Big-Data-Ökosystemen etabliert. Die Software kann fast alle Big-Data-Pakete der Open-Source-Welt installieren. Technisch ist die Verwendung von Apache Ambari zwar nicht zwingend erforderlich, da sich alle Pakete auch von Hand installieren lassen. Dabei müssten jedoch alle Abhängigkeiten manuell eingerichtet werden – das überlässt man lieber Ambari.
Apache Mesos dient zum Management von Clustern, die es dem Nutzer gegenüber als ein einziges hoch skalierbares System darstellt. Statt in einem Hadoop-Cluster neue Compute-Nodes anfordern zu müssen, kann man mit Mesos einfach mehr CPU-Leistung hinzufügen, die anschließend umgehend zur Verfügung steht. Anders als das Gros der in Java implementierten Big-Data-Pakete ist Apache Mesos in C/C++ geschrieben und enthält plattformspezifischen Code. Anpassungen müssen daher für alle unterstützten Systeme (Linux, Solaris und Windows) separat erfolgen. Mesos wird über Hadoop-Cluster hinaus häufig zur Cloud-Orchestrierung eingesetzt.
Big-Data-Systeme übernehmen die meisten verarbeiteten Daten von anderen Systemen. Daher spielt die Ausgestaltung des Dateneingangs eine entscheidende Rolle. Die Entscheidung für Queue, ETL oder Streaming hängt von verschiedenen fachlichen Aspekten ab. Dazu gehören das Datenvolumen und die Frequenz, in der Daten ankommen, aber auch die Wiederholbarkeit (können Daten noch mal geschickt werden?) und die Verfügbarkeit des Big-Data-Systems bei der Annahme von Daten (siehe Tabelle auf S. 68).

Wichtig ist auch zu entscheiden, was mit den Daten unmittelbar nach dem Eingang passieren soll. Sollen diese „nur“ abgespeichert oder müssen sie sofort verarbeitet werden? Im ersten Fall genügt eine Batch-Lösung, im zweiten Fall wird Streaming benötigt. Je nach Echtzeitanforderungen kommen auch hier nur bestimmte Lösungen infrage (siehe Tabelle).
Queue bedeutet Kafka
Zu Apache Kafka als Queue gibt es bei der skalierbaren Datenannahme keine echte Alternative. Dies drückt sich in der großen Popularität der ursprünglich bei LinkedIn entwickelten Software aus. Trotzdem gibt es bei Kafka funktionale Einschränkungen: So kann es passieren, dass die Software Nachrichten mehrmals zustellt („Deliver-at-least-once“-Garantie). Diesen Fall müssen die Clients, die die Daten aus der Kafka-Queue abholen, abfangen – eine „Deliver-exactly-once“-Garantie wäre hier einfacher.
Nicht nur deshalb erkauft man die hohe Geschwindigkeit und Skalierbarkeit von Kafka mit deutlich komplizierterer Client-Programmierung im Vergleich zu herkömmlichen Queues wie Apache ActiveMQ. Diese Einschränkungen muss man bereits bei der Planung und Architektur eines Systems beachten.