
Python-Praxis: Excel-Daten nutzen
Die pandas-Bibliothek bietet die Möglichkeit, mit Python Daten aus Excel-Arbeitsmappen auszulesen, zu bearbeiten und zu ändern.

(Bild: Heise Medien)
- Walter Saumweber
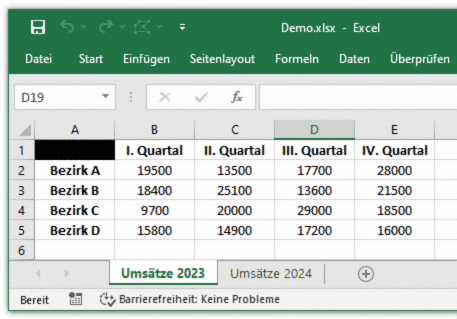
Programmseitige Zugriffe auf Excel sind für viele Anwendungsbereiche interessant. Daher verwundert es nicht, dass Python für diesen Zweck Bibliotheken zur Verfügung stellt. Außer pandas ist vor allem noch openpyxl zu nennen, wobei pandas selbst openpyxl in Teilen nutzt. Beide Bibliotheken unterstützen alle Excel-Formate, also auch den Makro-Dateityp .xlsm. Als Grundlage für die folgenden Codebeispiele dient eine Excel-Arbeitsmappe Demo.xlsx mit dem Arbeitsblatt Umsätze 2023. Die Tabelle ist mit je fünf Zeilen und Spalten bewusst einfach gehalten, aber natürlich lassen sich die folgenden Beispiele auch mit jeder anderen Excel-Arbeitsmappe nachvollziehen; die Größe des Tabellenblatts spielt dabei keine Rolle.

Die Beispieldateien zum Download
pandas installieren
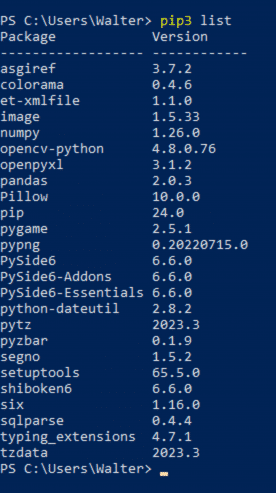
Die pandas-Bibliothek ist nicht im Standardumfang von Python enthalten und lässt sich auf der Konsole mit dem Befehl pip3 install pandas für Python 3 nachinstallieren. Die IDE PyCharm macht das Installieren von Bibliotheken besonders einfach. Es erkennt, falls eine Bibliothek nicht vorhanden ist, und bietet die Installation automatisch an. Dazu schreibt man den import-Befehl so in den Editor, als ob die Bibliothek schon vorhanden wäre. Beim Hovern mit der Maus über den rot unterkringelten Namen erscheint dann ein Pop-up-Fenster mit dem install-Befehl.
Die Bibliothek pandas nutzt wiederum die Bibliotheken NumPy und openpyxl, die die Installation von pandas normalerweise automatisch enthält. Es ist jedoch sinnvoll, sich davon zu überzeugen und sie gegebenenfalls nachzuinstallieren.

(Bild: Walter Saumweber)
Daten aus einem Excel-Tabellenblatt einlesen
Das Auslesen von Daten aus einem Excel-Tabellenblatt geschieht nach dem Import von pandas auf bequeme Weise mit der Funktion read_excel(). Als ersten Parameter übergibt man den Namen der auszulesenden Excel-Datei, gegebenenfalls mit Pfad. Standardmäßig, ohne weitere Parameter, liest read_excel() alle Daten des ersten Tabellenblatts ein.
import pandas
data_frame = pandas.read_excel('Demo.xlsx')Die Funktion speichert die gelesenen Excel-Daten in einem DataFrame (Klasse pandas.core.frame.DataFrame), und zwar zweidimensional, also praktisch wie in einem Excel-Arbeitsblatt. Somit enthält beispielsweise data_frame['I. Quartal'][0] den Wert der ersten Zelle der Spalte I. Quartal. Im Arbeitsblatt von Demo.xlsx ist das der Umsatz des Bezirks A im ersten Quartal (Zelle B2).
Um sich einen Überblick über die Struktur der Daten zu verschaffen, kann man mit print(data_frame) den kompletten DataFrame ausgeben oder mit print(data_frame['<Spaltenname>']) nur die Daten einer Spalte, beispielsweise print(data_frame['I. Quartal']). Ausgegeben werden zum Beispiel auch die Indizes der Zeilen, beginnend bei 0 unter den Spaltennamen. Die Spalten müssen dagegen immer mit Namen, also durch Angabe eines Strings, referenziert werden. Falls eine Spalte nicht existiert, stellt sich ein KeyError ein. Für den Fall, dass eine Spalte im Excel-Tabellenblatt einmal umbenannt wird, ist eine diesbezügliche Ausnahmebehandlung sinnvoll:
try:
print(data_frame['I. Quartal'])
except KeyError:
print('Die Spalte existiert nicht')Standardmäßig interpretiert die Funktion read_excel() die Daten der ersten Zeile eines Excel-Tabellenblatts als Spaltenüberschriften. Für Zellen, die in dieser Zeile leer sind, speichert der DataFrame den Wert Unnamed: <Index>, für die erste Zelle in der Beispieltabelle folglich den Wert Unnamed: 0. data_frame['Unnamed: 0'][<Index>] referenziert die Zeilenüberschriften dieser Tabelle – mit data_frame['Unnamed: 0'][2] erhält man beispielsweise den Bezirk C.
(Bild: Walter Saumweber)
Prüfen, ob eine Excel-Zelle leer ist
Einfache Datenzellen, die leer sind, werden im DataFrame mit nan (für „not a number“) gefüllt (in der Ausgabe erscheint jedoch das bekannte NaN). Daher erhalten Developer kein korrektes Ergebnis, wenn sie im Python-Code auf einen Leerstring prüfen. Beispielsweise ist die if-Bedingung if data_frame['I. Quartal'][1] == '' nicht geeignet, um über den erstellten DataFrame die zweite Zelle der Spalte I. Quartal dahin gehend zu prüfen. Aber auch Vergleiche mit 'nan' oder nan führen nicht zum Ziel.
Lösungen für dieses Problem gibt es mehrere. Zum einen stellt die pandas-Bibliothek für die Prüfung auf leere Zellen die Funktion isna zur Verfügung. Dieser übergibt man den Teil des DataFrames, der die Zelle repräsentiert. Die Inhaltsprüfung von Zelle B3 könnte so aussehen:
if pandas.isna(data_frame['I. Quartal'][1]):
print('Die Zelle ist leer')Die NumPy-Bibliothek bietet zum gleichen Zweck die Funktion isnan(). Der Aufruf unterscheidet sich nicht von dem der Funktion isna(). Es gibt noch eine weitere, recht elegante Möglichkeit: Entwicklerinnen und Entwickler machen sich den Umstand zunutze, dass nan das einzige Objekt ist, bei dem ein direkter Vergleich mit sich selbst ein False ergibt.
if data_frame['I. Quartal'][1] != data_frame['I. Quartal'][1]:
print('Die Zelle ist leer')Parameter von read_excel()
Für Bedingungen, die nicht dem Standard entsprechen, stellt die Funktion read_excel() verschiedene Parameter zur Verfügung. Der Parameter skiprows kommt zum Einsatz, wenn die relevanten Daten nicht in der ersten Zeile beginnen. Der an skiprows zugewiesene Wert steht für die Anzahl der Zeilen, die read_excel() überspringen soll, zum Beispiel:
data_frame = pandas.read_excel('Demo.xlsx', skiprows=3)Der Parameter sheet_name bestimmt das einzulesende Tabellenblatt, mit der folgenden Anweisung das zweite Tabellenblatt der Beispiel-Arbeitsmappe.
data_frame = pandas.read_excel('Demo.xlsx', sheet_name='Umsätze 2024')Anstelle des Namens eignet sich auch der Index, bei mehreren Tabellenblättern beispielsweise:
tabellenblaetter = [0, 1]
data_frames = pandas.read_excel('Demo.xlsx', sheet_name=tabellenblaetter)In diesem Fall erzeugt read_excel() ein Dictionary, das einen DataFrame für jedes Tabellenblatt enthält. Die Schlüssel bilden die Tabellenblätter-Indizes bzw. die Tabellenblattnamen. Die oben erzeugten DataFrames lassen sich mit data_frames[0] und data_frames[1] ansprechen.Der Parameter header gibt die Zeile mit den Spaltenüberschriften an, was erforderlich ist, wenn sie nicht die erste Zeile des Tabellenblatts ist. Die Angabe header=2 bedeutet zum Beispiel, dass sich die Zeilenüberschriften in der dritten Zeile des Tabellenblatts befinden. header=None teilt der read_excel() mit, dass die Excel-Tabelle keine Spaltenüberschriften enthält. Unabhängig davon weist names einer Liste die gewünschten Spaltennamen zu:
spalten = ['', 'I/24', 'II/24', 'III/24', 'IV/24']
data_frame = pandas.read_excel('Demo.xlsx', names=spalten)
print(data_frame)Die Ausgabe sieht so aus:
I/24 II/24 III/24 IV/24
0 Bezirk A 19500 13500 17700 28000
1 Bezirk B 18400 25100 13600 21500
2 Bezirk C 9700 20000 29000 18500
3 Bezirk D 15800 14900 17200 16000
Wichtig ist dabei: read_excel() erwartet in der names-Liste für jede Spalte genau eine Überschrift, auch für Zellen, die in der Überschriftenzeile leer sind. Da die Überschriftenzeile in der Excel-Tabelle fünf Spalten umfasst, muss auch die names-Liste genau fünf Elemente enthalten, andernfalls würde sich ein ValueError einstellen („Number of passed names did not match number of header fields in the file“).
Es ist aber zulässig – wie hier beim ersten Element geschehen – einen Leerstring zuzuweisen. In diesem Fall enthält der DataFrame für diese Spalte tatsächlich keine Überschrift, und nicht etwa den Text „Unnamed: “ mit anschließendem Spaltenindex, den read_excel() bei fehlenden Spaltenüberschriften automatisch zuweist, wenn die Funktion ohne names-Parameter aufgerufen wird.
Allerdings definiert names auch für Spalten ohne Überschrift eine solche.
spalten = ['Verkaufsbezirke', 'I/24', 'II/24', 'III/24', 'IV/24']Ein bisschen Vorsicht ist bei der gemeinsamen Verwendung der Parameter skiprows, names und header geboten, denn sie beeinflussen sich gegenseitig. Beispielsweise zählt die Überschriftenzeile der Excel-Tabelle beim skiprows-Wert nicht mit, wenn beim read_excel()-Aufruf gleichzeitig names verwendet wird, und bei einem skiprows-Wert von zum Beispiel 2 würde die Angabe header=0, ohne names, bedeuten, dass die Überschriftenzeile in der Excel-Tabelle nicht etwa die erste, sondern die dritte Zeile ist. Es ist also ratsam, sich in der Entwicklungsphase immer wieder davon zu überzeugen, dass das Ergebnis den Erwartungen entspricht.
Der Parameter nrows legt fest, wie viele Zeilen read_excel() in den DataFrame einliest. Beispielsweise speichert read_excel() mit nrows=2 im DataFrame zwei Datenzeilen plus Überschriftenzeile. Beim Standardwert für skiprows (None beziehungsweise 0) sind das die ersten drei Zeilen der Beispieltabelle (die Überschriftenzeile mitgerechnet). Falls ein Wert für skiprows angegeben ist, speichert read_excel() die Zeilen ab der entsprechenden Stelle.
Mit dem Parameter usecols lassen sich die einzulesenden Spalten beschränken. Diese müssen nicht unbedingt nebeneinanderliegen, sondern Entwicklerinnen und Entwickler können eine Liste mit Spaltennamen oder Indizes (aber nur eines von beiden) zuweisen. In Kombination mit names müssen die durch diesen Parameter definierten Spaltennamen angegeben werden.
spalten = ['Verkaufsbezirke', 'I/23', 'II/23', 'III/23', 'IV/23']
data_frame = pandas.read_excel('Demo.xlsx', names=spalten, usecols=['Verkaufsbezirke', 'II/23'])
print(data_frame)Hier die Ausgabe des obigen Listings:
Verkaufsbezirke II/23
0 Bezirk A 13500
1 Bezirk B 25100
2 Bezirk C 20000
3 Bezirk D 14900